
Read on for a glimpse into a reproducible pilot that combined the use of the Europeana.eu platform and APIs, pre-trained AI models, live code and semantic data modelling, human contributors on a crowdsourcing platform, a bias-aware thesaurus tool and data metrics, which led to the enrichment of a Ukrainian ethnographic collection on Europeana.eu through 55,000 annotation actions and almost 6,000 new metadata tags.
Citizen-led safeguarding of Ukrainian heritage
Since 2025, Web2Learn – together with the Universities of Luxembourg, Latvia, Kiev Taras Shevchenko, and the Europeana Foundation – has collaborated on AISTER, an Erasmus+ project which addresses AI-enabled citizen participation in safeguarding Ukrainian cultural heritage. Web2Learn contributes its expertise in citizen-driven innovation to the project utilising open-source technologies that foster education, training and active citizenship.

HITL Crowdsourcing Pilot Poster by Web2Learn incorporates Folk Painting "Portrait of a girl" as attributed above, incorporated into the present composition with additional permission from the rights holder.
The AISTER consortium has envisaged a series of workshops with the involvement of researchers, students and young professionals for the duration of the project. Five workshops led by Web2Learn online and onsite at the Library of the University of Latvia provided an opportunity to run a pilot: test a human-in-the-loop workflow to enrich digital collections of images through crowdsourcing and AI tools, inviting the workshop participants to engage with Ukrainian ethnographic heritage and become active contributors by enriching and validating AI-generated description tags.
The pilot was designed as an open and reproducible resource with detailed documentation to facilitate digital humanities research and training, and is made freely available for reuse by scholars, students and teachers, as well as for creative reuse.
Ukrainian folk art on Europeana.eu
In 2025 the Krovets Online Museum of Traditional Art of Ukraine, which has been operating since 2014 thanks to the voluntary efforts of the museum’s founders, published a dataset on Europeana.eu through the aggregator MUSEU, which comprises 3,840 artefacts of ethnographic heritage, including traditional costumes, textile crafts, folk art, material culture and photographs.
The images used for the pilot originate from this ethnographic collection. As part of the pilot, a Gallery of Ukrainian folk art was published on Europeana.eu, providing access to the museum’s folk art subcollection, which includes 312 artefacts classified as folk paintings or folk icons. Most paintings, depicting everyday rural life, folklore and religious themes, originate from the central ethnographical regions of Ukraine, Middle Podniprovia and Poltavshchyna, and date primarily to the early and mid-twentieth century.
The collection is composed primarily of genre scenes, landscapes and individual portraits. The folk paintings form visual narratives, offering snapshots of rural landscapes, religious traditions, folk art motifs and everyday material culture. Many of the details are easy to notice when looking at the images, but not always easy to discover through search.
The human-in-the-loop crowdsourcing pilot
The pilot aimed to create a new layer of visibility for Ukrainian folk art. It developed a workflow that combines the use of Europeana APIs, AI-based methods for natural language processing and computer vision, Jupyter Notebook as an interactive workspace for reproducible coding, and ethics-based data processing, together with public engagement via the crowdsourcing platform CrowdHeritage to create searchable, human-validated and ethically assessed description tags at large.
To get started, two Europeana APIs were used to fetch the gallery items and metadata, the Europeana User Set API for accessing user-generated galleries published on Europeana, and the Europeana Search API for metadata retrieval of content accessed on Europeana, modelled using the Europeana Data Model (EDM). Then, new descriptive annotations were generated with AI tools that employed open-source pre-trained AI models and libraries in natural language processing and computer vision. The automated annotations were generated in Jupyter Notebooks and serialised in JSON-LD according to the Web Annotation Data Model of the W3C (World Wide Web Consortium), to support their import into the CrowdHeritage crowdsourcing platform maintained by Datoptron.
In total, the pilot developed eight Jupyter Notebooks, which functioned as interactive computing environments that allow live coding and reproducibility to support the end-to-end execution of the data processing steps. The notebooks were implemented in Google Colab to enable real-time collaboration and co-editing and then transferred as an open repository on GitHub for version control, facilitating transparency and traceability of collaborative code optimisation. They cover the full data process of the pilot in sequential steps, which include:
Step 1: Automated annotation generation from textual metadata (NLP-based)
1i. Retrieve the items ID’s within the published Gallery of Ukrainian folk art using the Europeana User Set ΑPI and fetch textual metadata (e.g., titles, subjects) of the artefacts using the Europeana Search API.
1ii. Generate automated annotations (description tags) from the metadata using natural language processing (NLP) techniques, particularly rule-based heuristics and Named Entity Recognition (NER) using the open-source Python library spaCy.
Step 2: Automated annotation generation from images (computer vision-based)
2i. Download Gallery artefacts as images using the Europeana User Set API.
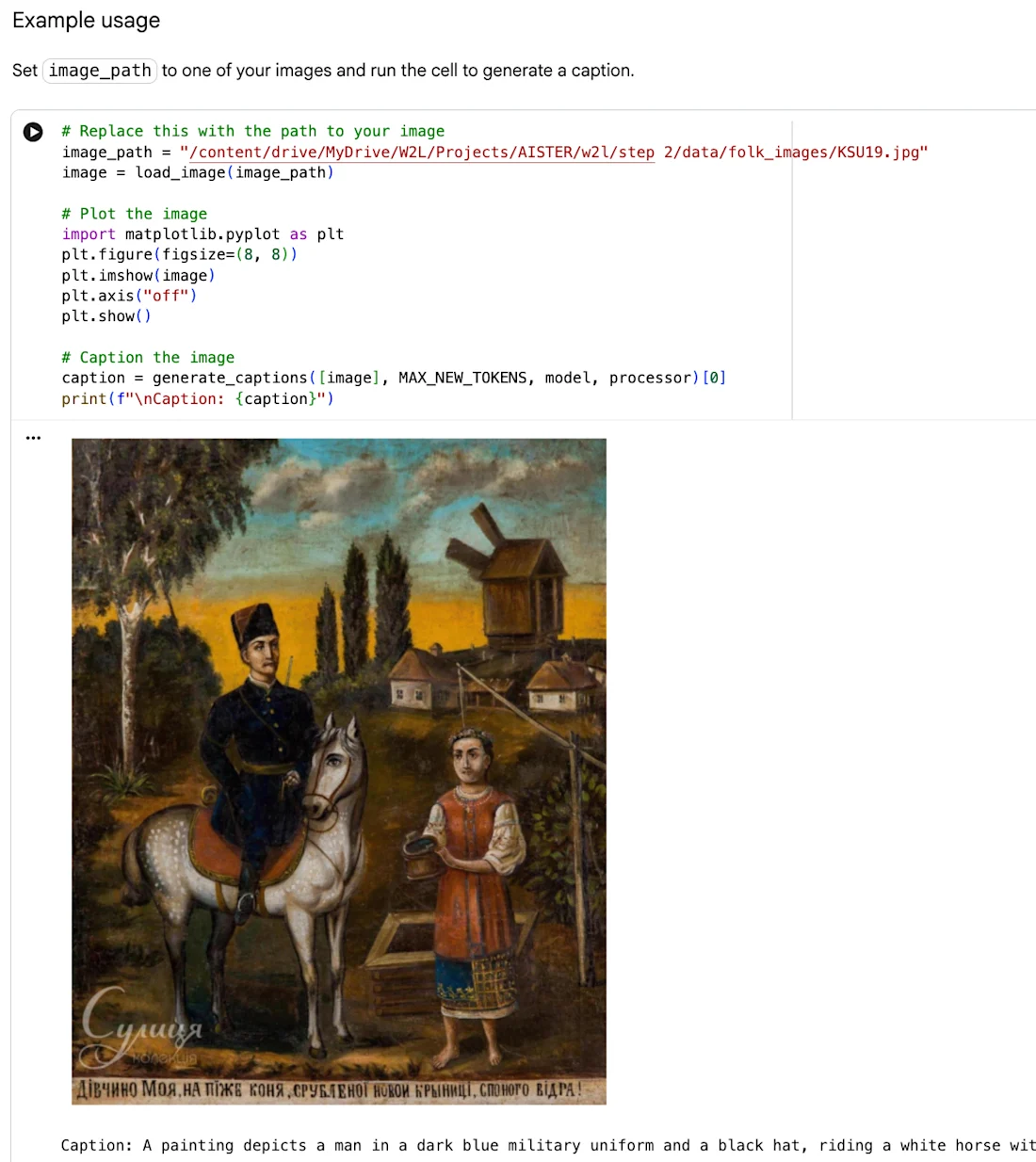
2ii. Generate descriptive image captions using computer vision techniques with pre-trained AI models, particularly variants of the open-source Qwen models – Qwen3-VL-2B-Instruct multimodal visual-language model (VLM) and Qwen3.5-4B large language model (LLM).
2iii. Generate automated annotations from the image captions.
Step 3: Preparation of automated annotations for crowdsourced validation (JSON-LD formatting)
3i. Format all generated annotations based on the W3C annotation model for direct ingestion in the crowdsourcing platform CrowdHeritage.
3ii. Convert the JSON-formatted final annotations into a machine-readable CSV and combine all annotations from the five crowdsourcing workshops.
Step 4: Data quality assurance and bias-aware screening of human-validated annotations
4i. Check final annotations against harmful, biased or contentious terms in the DE-BIAS Vocabulary through RDF-based thesaurus querying.
Over the course of five crowdsourcing workshops held on-site and online, 70 participants including researchers, university students and folk art experts reviewed AI-generated annotations, confirming accurate tags, rejecting misleading ones through upvotes and downvotes, and contributing additional annotations of their own.
Data insights and ethical assessment
The majority of images were enriched with 15 to 20 new descriptive tags each. Overall, almost 55,000 annotation actions were recorded, including tag generation, upvotes, and downvotes. The result is opening richer pathways for discovering and engaging with Ukrainian folk art. The post-campaign metrics reveal that most AI-generated annotations were accepted as accurate, with only a few being rejected.
These five AI-generated tags received the highest acceptance rates:
- icon
- painting
- man
- trees
- woman.
These five AI-generated tags received the highest rejection rates:
- cracks
- wear
- damage
- small object
- staff.
Applying an ethical impact assessment to the final annotations was treated as an important step in the pilot. A second layer of review was conducted to identify potentially problematic language and strengthen accountability. Screening the human-approved tags against the DE-BIAS Vocabulary identified one term, slave, which was subsequently revised to enslaved person per the recommendation. The vocabulary was applied as an ethical impact assessment measure prior to the final open dataset publication, taking into account the UNESCO ‘Recommendation on the Ethics of Artificial Intelligence’ (2022) and the ‘Ethical impact assessment’ tool (2023).
The development of the pilot and the understanding of its AI-related ethical dimensions was also informed by the AISTER data analysis study, which mapped 22 international research projects that use artificial intelligence and citizen participation for cultural heritage preservation in emergency contexts. The study classified the selected projects using the AISTER classification framework, which offers a systematic categorisation across 24 analytical dimensions designed for analysing AI-driven participatory heritage initiatives. The framework dimensions include cultural heritage domains, the citizen participation model (Shirk et al., 2012), and the cooperation model (Carayannis & Campbell, 2009), alongside AI-specific dimensions, including AI technology types, the rational agent model (Russell & Norvig, 2020, 4th ed.), the applied ethical AI typology (Morley et al., 2019), licence types and more. The study’s data insights are published as open-access interactive web visualisations that offer a comparative exploration of the field. The pilot workflow and findings are published in a forthcoming conference paper (Ziku, Zourou, & Kouzelis, 2026).
Conclusions
The pilot set out to create an open and reproducible pathway for using AI tools to process data at scale, combined with human participation, ethical assessment, and data insights, to support more accurate, accountable, metrics-driven, and enriched ways of discovering Ukrainian folk art. Sometimes the serendipitous journey into heritage begins with the word typed into a search box. And sometimes, the right words can bring a new collection to light.
The three most active contributors to the crowdsourcing campaign received an honorarium as well as gold, silver, and bronze badges respectively: Inna Kaika, student in English Language and Foreign Literature, Mykola Gogol State University; Daria Markova, student in Translation, Pryazovskyi State Technical University; Marko Lakhmatov, student in Cybersecurity, Pryazovskyi State Technical University.
Reflecting on her participation, Inna shared, ‘Ukrainian art reflects the resilience and creativity of our people, and sharing it is more important than ever. Driven by this passion, I joined the campaign to make cultural heritage more accessible. I especially enjoyed the annotation process and the exploration of the ethnographic collection. It was an honour to contribute to a project that brings together art and technology.’
Explore and reuse the pilot resources
Interested in applying similar methods to your own collections?
- View the crowdsourcing campaign for Ukrainian folk art on CrowdHeritage.
- Explore the human-in-the-loop crowdsourcing pilot.
- Reuse the open-source Jupyter Notebooks, which document the full workflow from data retrieval to AI-generated annotations and platform-ready exports.
- Access the open datasets on Zenodo’s open repository, which include the pilot’s data and outputs for preservation, citation, and reuse.
- Explore the interactive data visualisations and discover insights from 22 international research initiatives that use AI and citizen participation for cultural heritage preservation in emergency settings and beyond.
Acknowledgements
We would like to thank all AISTER project partners and collaborators, and particularly Yevgen Dmytruk at the Krovets Museum, Eirini Kaldeli at CrowdHeritage and Datoptron, Hugo Manguinhas at the Europeana Foundation, and Uldis Zariņš and Sanita Reinsone at the University of Latvia.
Selected references
- The documentation of the Jupyter Notebooks follows the criteria of quality assessment for Jupyter projects by GLAM institutions, as published in Candela, G., Chambers, S., & Sherratt, T. (2023). An approach to assess the quality of Jupyter projects published by GLAM institutions. Journal of the Association for Information Science and Technology, 74(13), 1550–1564.
- The pilot’s README documentation on GitHub adopts the structure of the KU Leuven Libraries Git-based dataset documentation. See: KU Leuven Libraries, Digitisation Department. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Version 01-beta2) [Data set]. Zenodo.
- M. Ziku, K. Zourou, and A. Kouzelis, 'AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow,' 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Venice, Italy, Sept. 7–9, 2026, in press.