
Прочетете нататък, за да видите възпроизводим пилотен проект, който комбинира използването на платформата Europeana.eu и API, предварително обучени модели на ИИ, живи кодове и семантично моделиране на данни, човешки участници в платформа за краудсорсинг, инструмент за тезаурус и показатели за данни, отчитащи предубежденията, което доведе до обогатяването на украинска етнографска колекция на Europeana.eu чрез 55 000 анотационни действия и почти 6 000 нови маркера за метаданни.
Ръководена от гражданите защита на украинското наследство
От 2025 г. Web2Learn — заедно с университетите в Люксембург, Латвия, Киев Тарас Шевченко и фондация Europeana — си сътрудничи по AISTER — проект по програма „Еразъм+“, който е насочен към гражданското участие на ИИ в опазването на украинското културно наследство. Web2Learn допринася със своя опит в иновациите, насочени към гражданите, към проекта, използвайки технологии с отворен код, които насърчават образованието, обучението и активното гражданство.

HITL Crowdsourcing Pilot Poster by Web2Learn включва Фолклорна живопис "Портрет на момиче", както е приписано по-горе, включена в настоящата композиция с допълнително разрешение от носителя на правата.
Консорциумът AISTER предвижда поредица от семинари с участието на изследователи, студенти и млади специалисти по време на проекта. Пет семинара, ръководени от Web2Learn онлайн и на място в библиотеката на Латвийския университет, предоставиха възможност за провеждане на пилотен проект: изпробване на работен процес „човек в кръга“, за да се обогатят цифровите колекции от изображения чрез краудсорсинг и инструменти с ИИ, като участниците в семинара се приканват да се ангажират с украинското етнографско наследство и да станат активни участници чрез обогатяване и валидиране на генерираните от ИИ етикети за описание.
Пилотният проект е замислен като отворен и възпроизводим ресурс с подробна документация за улесняване на научните изследвания и обучението в областта на цифровите хуманитарни науки и е свободно достъпен за повторно използване от учени, студенти и учители, както и за творческо повторно използване.
Украинско народно изкуство на Europeana.eu
През 2025 г. онлайн музеят за традиционно изкуство на Украйна „Кровец“, който функционира от 2014 г. благодарение на доброволните усилия на основателите на музея, публикува набор от данни на Europeana.eu чрез агрегатора MUSEU, който включва 3840 артефакта от етнографското наследство, включително традиционни костюми, текстилни занаяти, народно изкуство, материална култура и фотографии.
Изображенията, използвани за пилота, произхождат от тази етнографска колекция. Като част от пилотния проект на Europeana.eu беше публикувана галерия за украинско народно изкуство, предоставяща достъп до подколекцията за народно изкуство на музея, която включва 312 артефакта, класифицирани като народни картини или народни икони. Повечето картини, изобразяващи всекидневния селски живот, фолклора и религиозните теми, произхождат от централните етнографски райони на Украйна, Средна Поднипровия и Полтавщина и датират предимно от началото и средата на ХХ век.
Колекцията е съставена предимно от жанрови сцени, пейзажи и индивидуални портрети. Фолклорните картини формират визуални разкази, предлагащи моментни снимки на селски пейзажи, религиозни традиции, мотиви от народното изкуство и ежедневна материална култура. Много от детайлите са лесни за забелязване, когато гледате изображенията, но не винаги е лесно да се открият чрез търсене.
Пилотът за краудсорсинг на хора в контура
Пилотният проект имаше за цел да създаде нов слой видимост за украинското народно изкуство. Той разработи работен процес, който съчетава използването на API на Europeana, основани на ИИ методи за обработка на естествен език и компютърно зрение, Jupyter Notebook като интерактивно работно пространство за възпроизводимо кодиране и основана на етиката обработка на данни, заедно с обществена ангажираност чрез платформата за краудсорсинг CrowdHeritage за създаване на етикети за описание, които могат да бъдат търсени, валидирани от човека и оценени от етична гледна точка като цяло.
За да се започне, бяха използвани два API на Europeana за извличане на елементите и метаданните на галерията, API на набора от потребители на Europeana за достъп до генерирани от потребителите галерии, публикувани в Europeana, и API на Europeana за търсене на метаданни за съдържание, достъпно в Europeana, моделирано чрез модела на данни на Europeana (EDM). След това бяха генерирани нови описателни анотации с инструменти на ИИ, които използваха предварително обучени модели на ИИ с отворен код и библиотеки в обработката на естествен език и компютърното зрение. Автоматизираните анотации са генерирани в Jupyter Notebooks и сериализирани в JSON-LD съгласно Web Annotation Data Model of the W3C (World Wide Web Consortium), за да се подпомогне тяхното импортиране в платформата CrowdHeritage crowdsourcing, поддържана от Datoptron.
Като цяло, пилотът разработи осем Jupyter Notebooks, които функционираха като интерактивни компютърни среди, които позволяват кодиране на живо и възпроизводимост, за да поддържат изпълнението от край до край на стъпките за обработка на данни. Бележниците бяха внедрени в Google Colab, за да позволят сътрудничество и съвместно редактиране в реално време и след това прехвърлени като отворено хранилище в GitHub за контрол на версиите, улеснявайки прозрачността и проследимостта на съвместната оптимизация на кода. Те обхващат целия процес на обработване на данни на пилотния проект в последователни стъпки, които включват:
Стъпка 1: Генериране на автоматизирани анотации от текстови метаданни (въз основа на NLP)
1и. Извличане на идентификационните номера на предметите в публикуваната галерия за украинско народно изкуство с помощта на потребителския набор ΑPI на Europeana и извличане на текстови метаданни (напр. заглавия, теми) на артефактите с помощта на API за търсене на Europeana.
1ii. Генериране на автоматизирани анотации (описание тагове) от метаданните, като се използват техники за обработка на естествен език (NLP), по-специално евристика, основана на правила, и разпознаване на имена на субекти (NER), като се използва библиотеката с отворен код Python spaCy.
Стъпка 2: Генериране на автоматизирани анотации от изображения (базирани на компютърно зрение)
2и. Изтегляне на артефакти от галерията като изображения с помощта на API за потребителския набор на Europeana.
2ii. Генериране на описателни изображения с помощта на техники за компютърно зрение с предварително обучени модели на ИИ, по-специално варианти на моделите с отворен код Qwen — мултимодален визуален езиков модел Qwen3-VL-2B-Instruct (VLM) и голям езиков модел Qwen3.5-4B (LLM).
2iii. Генериране на автоматизирани анотации от надписите на изображението.
Стъпка 3: Изготвяне на автоматизирани анотации за валидиране чрез краудсорсинг (форматиране JSON-LD)
3и. Форматирайте всички генерирани анотации въз основа на модела за анотация W3C за директно поглъщане в платформата за краудсорсинг CrowdHeritage.
3ii. Преобразувайте финалните анотации, форматирани от JSON, в машинно четима CSV и комбинирайте всички анотации от петте семинара за краудсорсинг.
Стъпка 4: Осигуряване на качеството на данните и проверка за предубеденост на валидираните от човека анотации
4и. Проверете окончателните анотации срещу вредни, пристрастни или спорни термини в речника DE-BIAS чрез търсене в тезауруса, базиран на RDF.
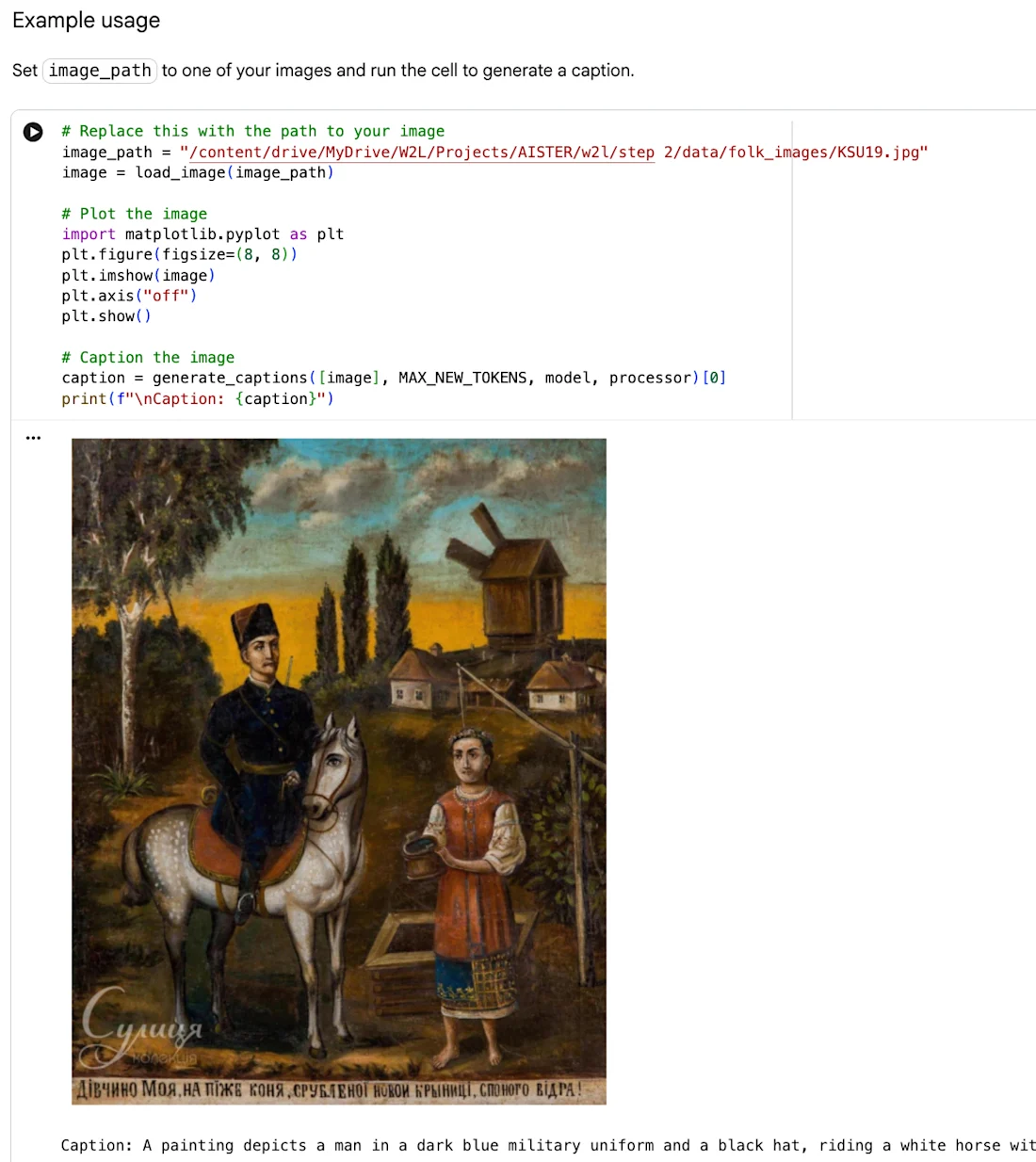
В хода на пет семинара за краудсорсинг, проведени на място и онлайн, 70 участници, включително изследователи, студенти и експерти по народно изкуство, прегледаха генерираните от ИИ анотации, потвърдиха точните етикети, отхвърлиха подвеждащите чрез гласове нагоре и надолу и допринесоха със свои собствени допълнителни анотации.
Прозрения за данните и етична оценка
По-голямата част от изображенията са обогатени с 15 до 20 нови описателни тагове всеки. Като цяло са записани почти 55 000 действия за анотация, включително генериране на етикети, upvotes и downvotes. Резултатът е откриване на по-богати пътища за откриване и ангажиране с украинското народно изкуство. Показателите след кампанията показват, че повечето генерирани от ИИ анотации са приети за точни, като само няколко от тях са отхвърлени.
Тези пет маркера, генерирани от ИИ, са получили най-висок процент на приемане:
- икона
- живопис
- човек
- дървета
- жена.
Тези пет маркера, генерирани от ИИ, са получили най-висок процент на отхвърляне:
- пукнатини
- носи
- щети
- малък обект
- персонал.
Прилагането на оценка на етичното въздействие към окончателните анотации беше разгледано като важна стъпка в пилотния проект. Беше проведено второ ниво на преглед, за да се идентифицира потенциално проблематичен език и да се засили отчетността. Проверката на одобрените от човека етикети срещу речника DE-BIAS идентифицира един термин, роб, който впоследствие беше преразгледан на поробен човек съгласно препоръката. Речникът беше прилаган като мярка за оценка на етичното въздействие преди окончателното публикуване на набора от свободно достъпни данни, като бяха взети предвид Препоръката на ЮНЕСКО относно етиката на изкуствения интелект (2022 г.) и инструментът „Оценка на етичното въздействие“ (2023 г.).
Разработването на пилотния проект и разбирането на неговите етични измерения, свързани с ИИ, бяха подкрепени и от проучването за анализ на данни AISTER, в което бяха очертани 22 международни научноизследователски проекта, които използват изкуствен интелект и гражданско участие за опазване на културното наследство в извънредни ситуации. Проучването класифицира избраните проекти, като използва рамката за класификация AISTER, която предлага систематична категоризация в 24 аналитични измерения, предназначени за анализ на основани на ИИ инициативи за участие в културното наследство. Рамковите измерения включват областите на културното наследство, модела на участие на гражданите (Shirk et al., 2012 г.) и модела на сътрудничество (Carayannis & Campbell, 2009 г.), наред със специфичните за ИИ измерения, включително видовете технологии с ИИ, модела на рационалните агенти (Russell & Norvig, 2020 г., 4-то изд.), приложната етична типология на ИИ (Morley et al., 2019 г.), видовете лицензи и др. Данните от проучването се публикуват като интерактивни уеб визуализации със свободен достъп, които предлагат сравнително проучване на областта. Пилотният работен процес и констатациите са публикувани в предстоящ документ от конференцията (Ziku, Zourou, & Kouzelis, 2026 г.).
Заключения
Пилотният проект имаше за цел да създаде отворен и възпроизводим път за използване на инструменти с ИИ за обработване на данни в голям мащаб, съчетан с човешко участие, етична оценка и прозрения на данни, за да се подкрепят по-точни, отговорни, основани на показатели и обогатени начини за откриване на украинското народно изкуство. Понякога случайното пътуване в наследството започва с думата, въведена в поле за търсене. И понякога правилните думи могат да доведат до нова колекция.
Тримата най-активни участници в краудсорсинг кампанията получиха хонорар, както и златни, сребърни и бронзови значки: Инна Кайка, студент по английски език и чужда литература, държавен университет „Микола Гогол“; Дария Маркова, студент по превод, Прязовски държавен технически университет; Марко Лахматов, студент по киберсигурност, Прязовски държавен технически университет.
Размишлявайки върху участието си, Инна сподели: „Украинското изкуство отразява устойчивостта и творчеството на нашите хора и споделянето му е по-важно от всякога. Водена от тази страст, аз се присъединих към кампанията, за да направя културното наследство по-достъпно. Особено ми хареса процесът на анотация и изследването на етнографската колекция. За мен беше чест да допринеса за проект, който обединява изкуството и технологиите.“
Проучване и повторно използване на пилотните ресурси
Интересувате ли се от прилагането на подобни методи в собствените си колекции?
- Вижте краудсорсинг кампанията за украинско народно изкуство в CrowdHeritage.
- Разгледайте пилотния проект за краудсорсинг „човек в контура“.
- Повторно използване на Jupyter Notebooks с отворен код, които документират пълния работен процес от извличането на данни до генерираните от ИИ анотации и готовия за платформи износ.
- Достъп до отворените набори от данни в отвореното хранилище на Zenodo, които включват данните и резултатите от пилотния проект за съхранение, цитиране и повторна употреба.
- Разгледайте интерактивните визуализации на данни и открийте информация от 22 международни научноизследователски инициативи, които използват ИИ и гражданското участие за опазване на културното наследство в извънредни ситуации и извън тях.
Потвърждения
Бихме искали да благодарим на всички партньори и сътрудници по проекта AISTER, и по-специално на Евген Дмитрук в музея в Кравец, Ейрини Калдели в CrowdHeritage и Datoptron, Хюго Мангуинхас във фондация Europeana и Улдис Заринш и Санита Рейнсоне в Латвийския университет.
Избрани препратки
- Документацията на тетрадките на Jupyter следва критериите за оценка на качеството на проектите на Jupyter от институциите на GLAM, публикувани в Candela, G., Chambers, S., & Sherratt, T. (2023 г.). Подход за оценка на качеството на проектите Jupyter, публикуван от институциите на GLAM. Списание на Асоциацията за информационни науки и технологии, 74(13), 1550–1564.
- Документацията README на пилотния проект в GitHub възприема структурата на документацията за набора от данни, базирана на Git, на библиотеките KU Leuven. Вж.: KU Leuven Libraries, отдел „Цифровизация“. (2019). Наборът от данни за събиране на портрети на библиотеките на КУ Льовен, специални колекции (версия 01-бета2) [набор от данни]. Аз съм Зенодо.
- M. Ziku, K. Zourou и A. Kouzelis, „AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow,’ 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Венеция, Италия, 7—9 септември 2026 г., в пресата.