
Lees verder voor een kijkje in een reproduceerbare pilot die het gebruik van het Europeana.eu-platform en API's, vooraf opgeleide AI-modellen, live code en semantische gegevensmodellering, menselijke bijdragers op een crowdsourcingplatform, een biasbewuste thesaurustool en gegevensstatistieken combineerde, wat leidde tot de verrijking van een Oekraïense etnografische collectie op Europeana.eu door middel van 55.000 annotatieacties en bijna 6 000 nieuwe metadatatags.
Burgergeleide bescherming van Oekraïens erfgoed
Sinds 2025 werkt Web2Learn samen met de universiteiten van Luxemburg, Letland, Kiev Taras Shevchenko en de Europeana Foundation aan AISTER, een Erasmus+-project dat op AI gebaseerde burgerparticipatie bij de bescherming van Oekraïens cultureel erfgoed aanpakt. Web2Learn draagt zijn expertise op het gebied van burgergestuurde innovatie bij aan het project waarbij gebruik wordt gemaakt van opensourcetechnologieën die onderwijs, opleiding en actief burgerschap bevorderen.

HITL Crowdsourcing Pilot Poster van Web2Learn bevat Folk Painting "Portret van een meisje" zoals hierboven toegeschreven, opgenomen in de huidige compositie met extra toestemming van de rechthebbende.
Het AISTER-consortium heeft een reeks workshops gepland met de betrokkenheid van onderzoekers, studenten en jonge professionals voor de duur van het project. Vijf workshops onder leiding van Web2Learn online en onsite in de bibliotheek van de Universiteit van Letland boden de gelegenheid om een pilot uit te voeren: een human-in-the-loop-workflow te testen om digitale collecties van beelden te verrijken door middel van crowdsourcing en AI-instrumenten, waarbij de deelnemers aan de workshop worden uitgenodigd om zich bezig te houden met Oekraïens etnografisch erfgoed en actieve bijdragers te worden door door door AI gegenereerde beschrijvingstags te verrijken en te valideren.
De pilot is ontworpen als een open en reproduceerbare bron met gedetailleerde documentatie om onderzoek en opleiding op het gebied van digitale geesteswetenschappen te vergemakkelijken, en wordt vrij beschikbaar gesteld voor hergebruik door wetenschappers, studenten en docenten, evenals voor creatief hergebruik.
Oekraïense volkskunst op Europeana.eu
In 2025 publiceerde het Krovets Online Museum voor traditionele kunst van Oekraïne, dat sinds 2014 actief is dankzij de vrijwillige inspanningen van de oprichters van het museum, een dataset op Europeana.eu via de aggregator MUSEU, die 3 840 voorwerpen van etnografisch erfgoed omvat, waaronder traditionele kostuums, textielambachten, volkskunst, materiaalcultuur en foto’s.
De beelden die voor de pilot zijn gebruikt, zijn afkomstig uit deze etnografische collectie. Als onderdeel van de proef werd op Europeana.eu een galerij van Oekraïense volkskunst gepubliceerd, die toegang biedt tot de deelcollectie volkskunst van het museum, die 312 kunstvoorwerpen omvat die als volksschilderijen of volksiconen zijn geclassificeerd. De meeste schilderijen, die het dagelijks leven op het platteland, folklore en religieuze thema's uitbeelden, zijn afkomstig uit de centrale etnografische regio's van Oekraïne, Midden-Podniprovia en Poltavshchyna, en dateren voornamelijk uit het begin en midden van de twintigste eeuw.
De collectie bestaat voornamelijk uit genrescènes, landschappen en individuele portretten. De volksschilderijen vormen visuele verhalen en bieden snapshots van landelijke landschappen, religieuze tradities, volkskunstmotieven en alledaagse materiële cultuur. Veel van de details zijn gemakkelijk op te merken bij het bekijken van de afbeeldingen, maar niet altijd gemakkelijk te ontdekken door middel van zoeken.
De pilot van human-in-the-loop crowdsourcing
Het proefproject was gericht op het creëren van een nieuwe zichtbaarheidslaag voor Oekraïense volkskunst. Er werd een workflow ontwikkeld die het gebruik van API’s van Europeana, op AI gebaseerde methoden voor natuurlijke taalverwerking en computervisie, Jupyter Notebook als interactieve werkruimte voor reproduceerbare codering en op ethiek gebaseerde gegevensverwerking combineert met publieke betrokkenheid via het crowdsourcingplatform CrowdHeritage om doorzoekbare, door mensen gevalideerde en ethisch beoordeelde beschrijvingstags in het algemeen te creëren.
Om aan de slag te gaan, werden twee Europeana API's gebruikt om de galerijitems en metagegevens op te halen, de Europeana User Set API voor toegang tot door gebruikers gegenereerde galerijen die op Europeana zijn gepubliceerd, en de Europeana Search API voor het ophalen van metagegevens van inhoud waartoe op Europeana toegang is verkregen, gemodelleerd met behulp van het Europeana Data Model (EDM). Vervolgens werden nieuwe beschrijvende annotaties gegenereerd met AI-tools die gebruikmaakten van open-source vooraf getrainde AI-modellen en -bibliotheken in natuurlijke taalverwerking en computervisie. De geautomatiseerde annotaties werden gegenereerd in Jupyter Notebooks en geserialiseerd in JSON-LD volgens het Web Annotation Data Model van het W3C (World Wide Web Consortium), ter ondersteuning van hun import in het CrowdHeritage crowdsourcing platform dat wordt onderhouden door Datoptron.
In totaal ontwikkelde de pilot acht Jupyter Notebooks, die fungeerden als interactieve computeromgevingen die live codering en reproduceerbaarheid mogelijk maken om de end-to-end uitvoering van de gegevensverwerkingsstappen te ondersteunen. De notebooks zijn geïmplementeerd in Google Colab om realtime samenwerking en co-editing mogelijk te maken en vervolgens overgedragen als een open repository op GitHub voor versiebeheer, waardoor transparantie en traceerbaarheid van collaboratieve code-optimalisatie worden vergemakkelijkt. Zij bestrijken het volledige gegevensproces van de piloot in opeenvolgende stappen, waaronder:
Stap 1: Geautomatiseerde annotatie generatie van tekstuele metadata (NLP-gebaseerd)
1i. Haal de items ID's op in de gepubliceerde Gallery of Ukrainian folk art met behulp van de Europeana User Set ΑPI en haal tekstuele metadata (bijv. titels, onderwerpen) van de artefacten op met behulp van de Europeana Search API.
1ii. Genereer geautomatiseerde annotaties (beschrijvingstags) uit de metadata met behulp van technieken voor natuurlijke taalverwerking (NLP), met name op regels gebaseerde heuristiek en Named Entity Recognition (NER) met behulp van de open-source Python-bibliotheek spaCy.
Stap 2: Geautomatiseerde annotatie op basis van afbeeldingen (gebaseerd op computervisie)
2i. Download Galerij-artefacten als afbeeldingen met behulp van de Europeana User Set API.
2ii. Genereer beschrijvende beeldbijschriften met behulp van computervisietechnieken met vooraf opgeleide AI-modellen, met name varianten van de open-source Qwen-modellen – Qwen3-VL-2B-Instruct multimodaal visueel taalmodel (VLM) en Qwen3.5-4B groot taalmodel (LLM).
2iii. Genereer geautomatiseerde annotaties van de afbeeldingsbijschriften.
Stap 3: Voorbereiding van geautomatiseerde annotaties voor crowdsourced validatie (JSON-LD-opmaak)
3i. Formatteer alle gegenereerde annotaties op basis van het W3C-annotatiemodel voor directe inname in het crowdsourcingplatform CrowdHeritage.
3ii. Zet de JSON-geformatteerde eindaantekeningen om in een machineleesbare CSV en combineer alle aantekeningen uit de vijf crowdsourcingworkshops.
Stap 4: Gegevenskwaliteitsborging en biasbewuste screening van door mensen gevalideerde annotaties
4i. Controleer de laatste annotaties tegen schadelijke, bevooroordeelde of controversiële termen in de DE-BIAS-woordenlijst door middel van RDF-gebaseerde thesaurusquery's.
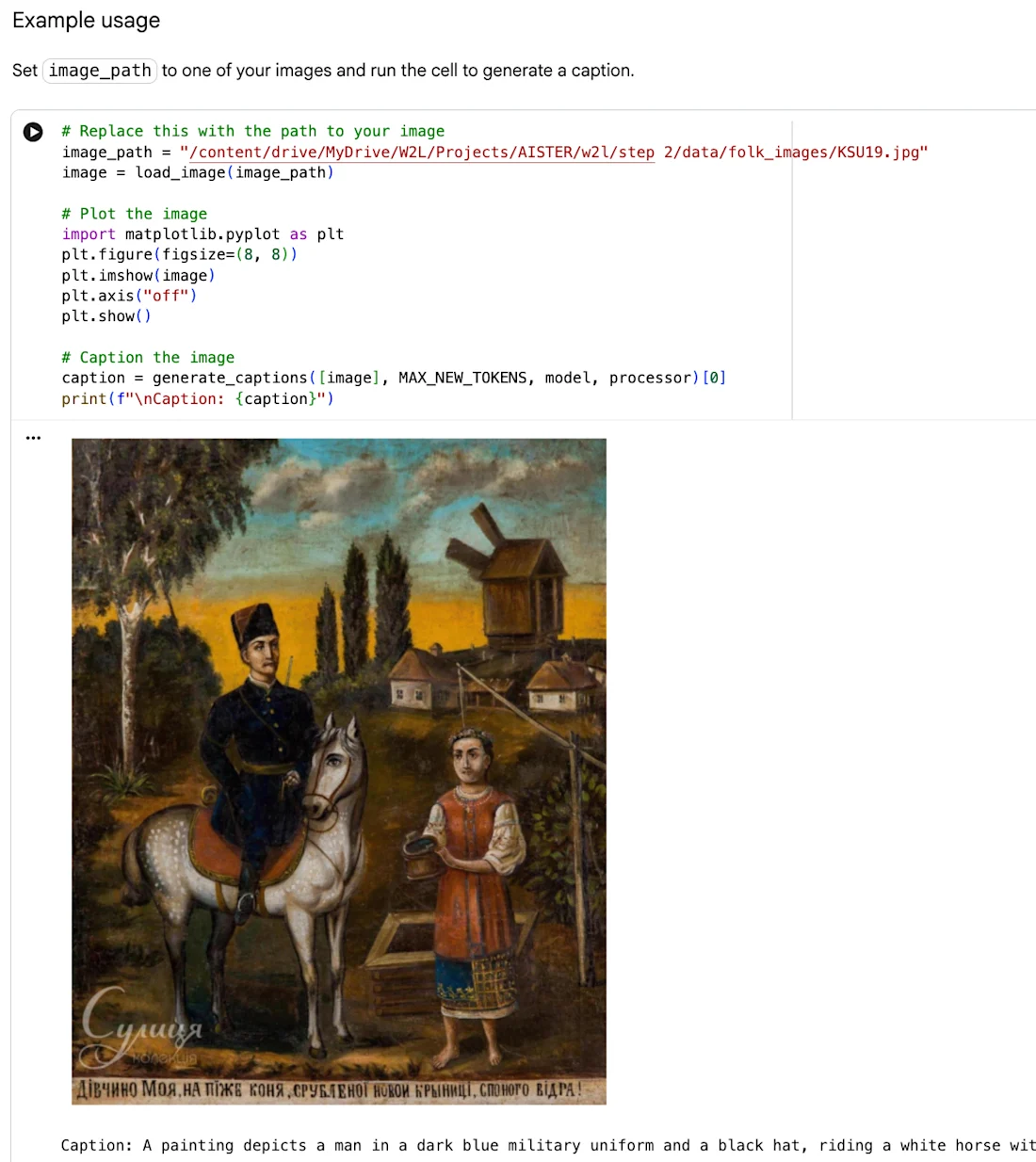
In de loop van vijf crowdsourcing-workshops die ter plaatse en online werden gehouden, beoordeelden 70 deelnemers, waaronder onderzoekers, universiteitsstudenten en experts op het gebied van volkskunst, door AI gegenereerde annotaties, bevestigden ze nauwkeurige tags, verwierpen ze misleidende tags via upvotes en downvotes en droegen ze zelf aanvullende annotaties bij.
Gegevensinzichten en ethische beoordeling
De meeste afbeeldingen werden verrijkt met 15 tot 20 nieuwe beschrijvende tags. In totaal werden bijna 55.000 annotatieacties geregistreerd, waaronder taggeneratie, upvotes en downvotes. Het resultaat is het openen van rijkere wegen voor het ontdekken van en het aangaan met Oekraïense volkskunst. De post-campagne statistieken blijkt dat de meeste AI-gegenereerde annotaties werden geaccepteerd als nauwkeurig, met slechts een paar wordt afgewezen.
Deze vijf door AI gegenereerde tags ontvingen de hoogste acceptatiepercentages:
- pictogram
- schilderen
- man
- bomen
- vrouw.
Deze vijf door AI gegenereerde tags kregen de hoogste afwijzingspercentages:
- scheuren
- draag
- schade
- klein voorwerp
- personeel.
Het toepassen van een ethische effectbeoordeling op de definitieve annotaties werd behandeld als een belangrijke stap in de pilot. Een tweede toetsingslaag werd uitgevoerd om potentieel problematische taal te identificeren en de verantwoordingsplicht te versterken. Het screenen van de door de mens goedgekeurde tags tegen de DE-BIAS-woordenlijst identificeerde één term, slaaf, die vervolgens werd herzien naar tot slaaf gemaakte persoon volgens de aanbeveling. De woordenschat werd voorafgaand aan de definitieve publicatie van de open dataset als ethische effectbeoordelingsmaatregel toegepast, rekening houdend met de Unesco-aanbeveling over de ethiek van artificiële intelligentie (2022) en het instrument voor ethische effectbeoordeling (2023).
De ontwikkeling van het proefproject en het inzicht in de ethische dimensies ervan op het gebied van AI zijn ook gebaseerd op de AISTER-gegevensanalyse, waarin 22 internationale onderzoeksprojecten in kaart zijn gebracht die gebruikmaken van artificiële intelligentie en burgerparticipatie voor het behoud van cultureel erfgoed in noodsituaties. In de studie werden de geselecteerde projecten ingedeeld aan de hand van het AISTER-classificatiekader, dat een systematische categorisering biedt over 24 analytische dimensies die zijn ontworpen voor het analyseren van AI-gedreven participatieve erfgoedinitiatieven. De kaderdimensies omvatten domeinen van cultureel erfgoed, het model voor burgerparticipatie (Shirk et al., 2012) en het samenwerkingsmodel (Carayannis & Campbell, 2009), naast AI-specifieke dimensies, waaronder AI-technologietypen, het rational agent-model (Russell & Norvig, 2020, 4e ed.), de toegepaste ethische AI-typologie (Morley et al., 2019), licentietypen en meer. De gegevensinzichten van de studie worden gepubliceerd als open-access interactieve webvisualisaties die een vergelijkende verkenning van het veld bieden. De pilotworkflow en bevindingen worden gepubliceerd in een aanstaande conference paper (Ziku, Zourou, & Kouzelis, 2026).
Conclusies
De proef was bedoeld om een open en reproduceerbaar traject te creëren voor het gebruik van AI-instrumenten om gegevens op grote schaal te verwerken, in combinatie met menselijke participatie, ethische beoordeling en gegevensinzichten, ter ondersteuning van nauwkeurigere, verantwoordingsplichtige, metriekgestuurde en verrijkte manieren om Oekraïense volkskunst te ontdekken. Soms begint de serendipitous reis naar erfgoed met het woord dat in een zoekvak wordt getypt. En soms kunnen de juiste woorden een nieuwe collectie aan het licht brengen.
De drie meest actieve bijdragers aan de crowdsourcing-campagne ontvingen respectievelijk een honorarium en gouden, zilveren en bronzen badges: Inna Kaika, student Engelse taal en buitenlandse literatuur, Mykola Gogol State University; Daria Markova, studente Vertaling, Technische Universiteit Pryazovskyi; Marko Lakhmatov, student Cybersecurity, Technische Universiteit van de staat Pryazovskyi.
Nadenkend over haar deelname deelde Inna het volgende: “Oekraïense kunst weerspiegelt de veerkracht en creativiteit van onze mensen, en het delen ervan is belangrijker dan ooit. Gedreven door deze passie heb ik me aangesloten bij de campagne om cultureel erfgoed toegankelijker te maken. Ik heb vooral genoten van het annotatieproces en de verkenning van de etnografische collectie. Het was een eer om bij te dragen aan een project dat kunst en technologie samenbrengt.”
Verkennen en hergebruiken van de pilot resources
Geïnteresseerd in het toepassen van soortgelijke methoden op uw eigen collecties?
- Bekijk de crowdsourcing campagne voor Oekraïense volkskunst op CrowdHeritage.
- Bekijk de human-in-the-loop crowdsourcing pilot.
- Hergebruik de open-source Jupyter Notebooks, die de volledige workflow documenteren, van het ophalen van gegevens tot door AI gegenereerde annotaties en platformklare export.
- Toegang tot de open datasets in het open register van Zenodo, met inbegrip van de gegevens en outputs van het proefproject voor bewaring, citatie en hergebruik.
- Verken de interactieve datavisualisaties en ontdek inzichten uit 22 internationale onderzoeksinitiatieven die AI en burgerparticipatie gebruiken voor het behoud van cultureel erfgoed in noodsituaties en daarbuiten.
Erkenningen
We willen alle AISTER-projectpartners en -medewerkers bedanken, met name Yevgen Dmytruk in het Krovets Museum, Eirini Kaldeli in CrowdHeritage en Datoptron, Hugo Manguinhas bij de Europeana Foundation en Uldis Zariņš en Sanita Reinsone aan de Universiteit van Letland.
Geselecteerde referenties
- De documentatie van de Jupyter Notebooks volgt de criteria voor kwaliteitsbeoordeling voor Jupyter-projecten door GLAM-instellingen, zoals gepubliceerd in Candela, G., Chambers, S., & Sherratt, T. (2023). Een aanpak om de kwaliteit van Jupyter-projecten te beoordelen, gepubliceerd door GLAM-instellingen. Tijdschrift van de Vereniging voor Informatiewetenschap en Technologie, 74(13), 1550-1564.
- In de README-documentatie van de pilot op GitHub wordt de structuur van de Git-datasetdocumentatie van de KU Leuven Libraries overgenomen. Zie: KU Leuven Bibliotheken, afdeling Digitalisering. (2019). De Portretten Collectie Dataset van KU Leuven Bibliotheken, Bijzondere Collecties (Versie 01-beta2) [Gegevensset]. Zenodo.
- M. Ziku, K. Zourou en A. Kouzelis, 'AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow", IEEE International Conference on Cyber Humanities (IEEE-CH), Venetië, Italië, 7-9 september 2026, in de pers.