
Nahlédněte do reprodukovatelného pilotního projektu, který kombinoval používání platformy Europeana.eu a rozhraní API, předtrénované modely umělé inteligence, modelování živého kódu a sémantických dat, lidské přispěvatele na platformě crowdsourcingu, nástroj založený na předpojatosti tezauru a datové metriky, což vedlo k obohacení ukrajinské etnografické sbírky na Europeana.eu prostřednictvím 55 000 anotačních akcí a téměř 6 000 nových metadatových značek.
Ochrana ukrajinského dědictví pod vedením občanů
Od roku 2025 společnost Web2Learn spolu s lucemburskými univerzitami, lotyšskými univerzitami, kyjevským Tarasem Ševčenkem a nadací Europeana spolupracuje na projektu AISTER, což je projekt Erasmus+, který se zabývá účastí občanů na ochraně ukrajinského kulturního dědictví prostřednictvím umělé inteligence. Web2Learn přispívá svými odbornými znalostmi v oblasti inovací řízených občany k projektu využívajícímu technologie s otevřeným zdrojovým kódem, které podporují vzdělávání, odbornou přípravu a aktivní občanství.

Pilotní plakát HITL Crowdsourcing od společnosti Web2Learn zahrnuje lidovou malbu "Portrét dívky", jak je uvedeno výše, začleněnou do současné kompozice s dodatečným povolením držitele práv.
Konsorcium AISTER plánuje po dobu trvání projektu sérii workshopů za účasti výzkumných pracovníků, studentů a mladých odborníků. Pět workshopů vedených Web2Learn on-line a na místě v knihovně Lotyšské univerzity poskytlo příležitost spustit pilotní projekt: otestovat pracovní postup „human-in-the-loop“ s cílem obohatit digitální sbírky snímků prostřednictvím crowdsourcingu a nástrojů umělé inteligence a vyzvat účastníky workshopu, aby se zapojili do ukrajinského etnografického dědictví a stali se aktivními přispěvateli tím, že obohatí a ověří popisné štítky vytvořené umělou inteligencí.
Pilotní projekt byl navržen jako otevřený a reprodukovatelný zdroj s podrobnou dokumentací pro usnadnění výzkumu a odborné přípravy v oblasti digitálních humanitních věd a je volně k dispozici pro opakované použití učenci, studenty a učiteli, jakož i pro kreativní opakované použití.
Ukrajinské lidové umění na Europeana.eu
V roce 2025 zveřejnilo Krovets Online Museum of Traditional Art of Ukraine, které funguje od roku 2014 díky dobrovolnému úsilí zakladatelů muzea, prostřednictvím agregátoru MUSEU datový soubor na Europeana.eu, který zahrnuje 3 840 artefaktů etnografického dědictví, včetně tradičních kostýmů, textilních řemesel, lidového umění, hmotné kultury a fotografií.
Snímky použité pro pilota pocházejí z této etnografické sbírky. V rámci pilotního projektu byla na portálu Europeana.eu zveřejněna Galerie ukrajinského lidového umění, která poskytuje přístup do podsbírky lidového umění muzea, která zahrnuje 312 artefaktů klasifikovaných jako lidové obrazy nebo lidové ikony. Většina obrazů, zobrazující každodenní vesnický život, folklór a náboženská témata, pochází z centrálních etnografických oblastí Ukrajiny, Střední Podniprovie a Poltavshchyna a pochází především z počátku a poloviny dvacátého století.
Sbírka je složena především z žánrových scén, krajin a jednotlivých portrétů. Lidové obrazy tvoří vizuální narativy, které nabízejí snímky venkovské krajiny, náboženských tradic, motivů lidového umění a každodenní materiální kultury. Mnoho detailů je snadné si všimnout při pohledu na obrázky, ale ne vždy snadno zjistit pomocí vyhledávání.
Pilotní projekt "human-in-the-loop crowdsourcing"
Cílem pilotního projektu bylo vytvořit novou úroveň viditelnosti ukrajinského lidového umění. Vyvinul pracovní postup, který kombinuje používání rozhraní API Europeany, metody založené na umělé inteligenci pro zpracování přirozeného jazyka a počítačové vidění, Jupyter Notebook jako interaktivní pracovní prostor pro reprodukovatelné kódování a zpracování dat založené na etice, spolu se zapojením veřejnosti prostřednictvím crowdsourcingové platformy CrowdHeritage s cílem vytvořit obecně prohledávatelné, člověkem ověřené a eticky posouzené popisné štítky.
K načtení galerijních předmětů a metadat byla použita dvě rozhraní Europeana API, rozhraní Europeana User Set API pro přístup k galeriím generovaným uživateli zveřejněným na portálu Europeana a rozhraní Europeana Search API pro vyhledávání metadat obsahu zpřístupněného na portálu Europeana, modelované pomocí datového modelu Europeana (EDM). Poté byly vytvořeny nové popisné anotace s nástroji umělé inteligence, které využívaly předtrénované modely a knihovny umělé inteligence s otevřeným zdrojovým kódem pro zpracování přirozeného jazyka a počítačové vidění. Automatizované anotace byly generovány v Jupyter Notebooks a serializovány v JSON-LD podle datového modelu webové anotace W3C (World Wide Web Consortium) na podporu jejich importu do crowdsourcingové platformy CrowdHeritage spravované společností Datoptron.
Pilotní projekt vyvinul celkem osm notebooků Jupyter, které fungovaly jako interaktivní výpočetní prostředí umožňující živé kódování a reprodukovatelnost pro podporu komplexního provádění kroků zpracování dat. Notebooky byly implementovány v Google Colab, aby umožnily spolupráci a koeditaci v reálném čase a poté převedeny jako otevřené úložiště na GitHub pro správu verzí, což usnadňuje transparentnost a sledovatelnost optimalizace kódu pro spolupráci. Zahrnují celý datový proces pilotního projektu v postupných krocích, mezi něž patří:
Krok 1: Automatické generování anotací z textových metadat (na základě NLP)
čl. 1 písm. i) Načíst ID položek v rámci publikované Galerie ukrajinského lidového umění pomocí uživatelské sady Europeana User Set ΑPI a načíst textová metadata (např. názvy, předměty) artefaktů pomocí rozhraní API vyhledávání Europeana.
1ii. Generovat automatizované anotace (značky popisu) z metadat pomocí technik zpracování přirozeného jazyka (NLP), zejména heuristiky založené na pravidlech a rozpoznávání pojmenovaných entit (NER) pomocí open-source Python knihovny spaCy.
Krok 2: Automatické generování anotací z obrazů (založené na počítačovém vidění)
čl. 2 písm. i) Stáhněte si artefakty galerie jako obrázky pomocí rozhraní Europeana User Set API.
2ii. Generovat popisné obrazové titulky pomocí technik počítačového vidění s předem vyškolenými modely umělé inteligence, zejména varianty modelů Qwen s otevřeným zdrojovým kódem – Qwen3-VL-2B-Instruct multimodální vizuální jazykový model (VLM) a Qwen3.5-4B velký jazykový model (LLM).
2iii. Vygenerujte automatické anotace z titulků obrázků.
Krok 3: Příprava automatických anotací pro crowdsourcingovou validaci (formátování JSON-LD)
čl. 3 písm. i) Formátujte všechny generované anotace na základě anotačního modelu W3C pro přímé požití v crowdsourcingové platformě CrowdHeritage.
3ii. Převeďte závěrečné anotace ve formátu JSON do strojově čitelného CSV a kombinujte všechny anotace z pěti crowdsourcingových workshopů.
Krok 4: Zajišťování kvality údajů a prověřování poznámek ověřených člověkem s ohledem na předpojatost
čl. 4 písm. i) Zkontrolujte konečné anotace proti škodlivým, neobjektivním nebo sporným termínům ve slovníku DE-BIAS prostřednictvím dotazování tezauru založeného na RDF.
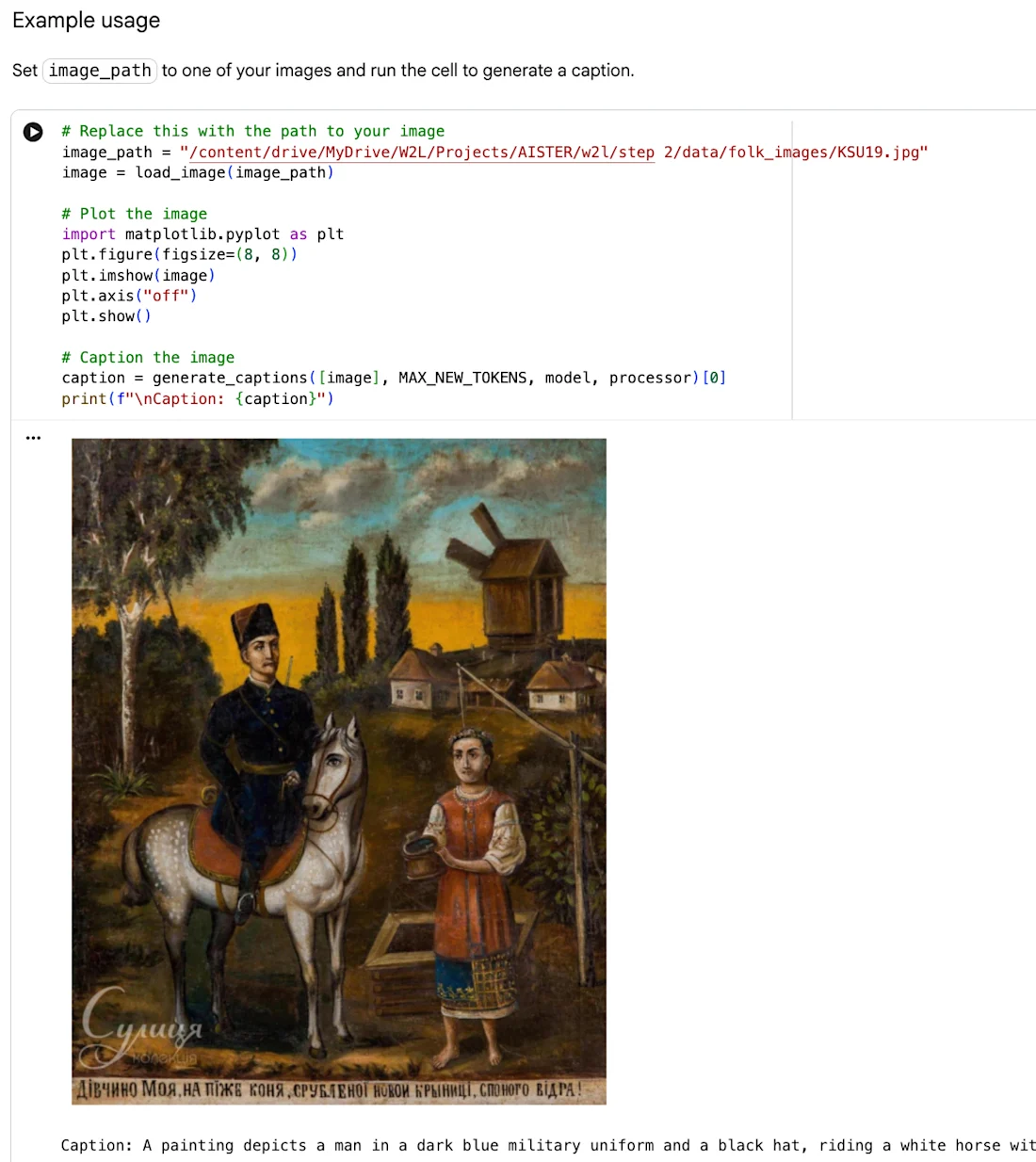
Během pěti crowdsourcingových workshopů, které se konaly na místě i online, 70 účastníků, včetně výzkumných pracovníků, vysokoškolských studentů a odborníků na lidové umění, přezkoumalo anotace vytvořené umělou inteligencí, potvrdilo přesné značky, odmítlo zavádějící prostřednictvím upvotů a downvotů a přispělo vlastními dodatečnými anotacemi.
Poznatky o datech a etické posouzení
Většina obrázků byla obohacena o 15 až 20 nových popisných značek. Celkově bylo zaznamenáno téměř 55 000 anotačních akcí, včetně generování tagů, upvotes a downvotes. Výsledkem je otevření bohatších cest pro objevování ukrajinského lidového umění a zapojení se do něj. Metriky po skončení kampaně ukazují, že většina anotací vytvořených umělou inteligencí byla přijata jako přesná, přičemž pouze několik z nich bylo odmítnuto.
Těchto pět značek vytvořených umělou inteligencí získalo nejvyšší míru přijetí:
- ikona
- malování
- muž
- stromy
- ženská.
Těchto pět značek vytvořených umělou inteligencí obdrželo nejvyšší míru odmítnutí:
- trhliny
- nosit
- poškození
- malý objekt
- zaměstnanci.
Uplatnění etického posouzení dopadů na závěrečné anotace bylo v pilotním projektu považováno za důležitý krok. Byla provedena druhá vrstva přezkumu s cílem určit potenciálně problematický jazyk a posílit odpovědnost. Screening lidsky schválených tagů proti slovníku DE-BIAS identifikoval jeden termín, slave, který byl následně revidován na zotročenou osobu podle doporučení. Slovní zásoba byla použita jako opatření pro posouzení etického dopadu před konečným zveřejněním otevřeného souboru údajů, s přihlédnutím k „doporučení UNESCO o etice umělé inteligence“ (2022) a k nástroji „posouzení etického dopadu“ (2023).
Vypracování pilotního projektu a pochopení jeho etických rozměrů souvisejících s umělou inteligencí bylo rovněž podloženo studií analýzy dat AISTER, která zmapovala 22 mezinárodních výzkumných projektů, které využívají umělou inteligenci a účast občanů na zachování kulturního dědictví v mimořádných situacích. Studie klasifikovala vybrané projekty pomocí klasifikačního rámce AISTER, který nabízí systematickou kategorizaci napříč 24 analytickými rozměry navrženými pro analýzu participativních iniciativ v oblasti kulturního dědictví založených na umělé inteligenci. Rámcový rozměr zahrnuje oblasti kulturního dědictví, model účasti občanů (Shirk et al., 2012) a model spolupráce (Carayannis & Campbell, 2009) spolu s rozměry specifickými pro umělou inteligenci, včetně typů technologií umělé inteligence, model racionálních činitelů (Russell & Norvig, 2020, 4. vyd.), aplikovanou etickou typologii umělé inteligence (Morley et al., 2019), typy licencí a další. Údaje získané v rámci studie jsou zveřejňovány jako interaktivní webové vizualizace s otevřeným přístupem, které nabízejí komparativní průzkum této oblasti. Pilotní pracovní postup a zjištění jsou zveřejněny v nadcházejícím konferenčním dokumentu (Ziku, Zourou, & Kouzelis, 2026).
Závěry
Cílem pilotního projektu bylo vytvořit otevřenou a reprodukovatelnou cestu pro využívání nástrojů umělé inteligence ke zpracování dat ve velkém měřítku v kombinaci s lidskou účastí, etickým hodnocením a poznatky o datech s cílem podpořit přesnější, odpovědnější a bohatší způsoby objevování ukrajinského lidového umění založené na metrikách. Někdy poklidná cesta do dědictví začíná zadáním slova do vyhledávacího pole. A někdy, správná slova mohou přinést novou kolekci na světlo.
Tři nejaktivnější přispěvatelé do crowdsourcingové kampaně obdrželi čestné uznání, stejně jako zlaté, stříbrné a bronzové odznaky: Inna Kaika, studentka anglického jazyka a zahraniční literatury, Mykola Gogol State University; Daria Marková, studentka překladatelství, Státní technická univerzita v Prjazovském; Marko Lakhmatov, student kybernetické bezpečnosti, Státní technická univerzita Pryazovskyj.
S ohledem na svou účast Inna sdílela: „Ukrajinské umění odráží odolnost a kreativitu našich lidí a jeho sdílení je důležitější než kdy jindy. Poháněn touto vášní jsem se připojil ke kampani za lepší přístupnost kulturního dědictví. Obzvláště se mi líbil proces anotací a zkoumání etnografické sbírky. Bylo mi ctí přispět k projektu, který spojuje umění a technologie.“
Prozkoumejte a znovu využijte pilotní zdroje
Máte zájem aplikovat podobné metody na své vlastní sbírky?
- Podívejte se na crowdsourcingovou kampaň pro ukrajinské lidové umění na CrowdHeritage.
- Prozkoumejte pilotní projekt „human-in-the-loop crowdsourcing“.
- Opětovné použití poznámkových bloků Jupyter s otevřeným zdrojovým kódem, které dokumentují plný pracovní postup od vyhledávání dat až po poznámky vytvořené umělou inteligencí a vývozy připravené pro platformu.
- Přístup k otevřeným datovým souborům v otevřeném úložišti společnosti Zenodo, které zahrnují data a výstupy pilotního projektu pro uchování, citaci a opakované použití.
- Prozkoumejte interaktivní vizualizace dat a objevte poznatky z 22 mezinárodních výzkumných iniciativ, které využívají umělou inteligenci a účast občanů k zachování kulturního dědictví v mimořádných situacích i mimo ně.
Potvrzení
Rádi bychom poděkovali všem partnerům a spolupracovníkům projektu AISTER, zejména Jevgenu Dmytrukovi z Krovetsova muzea, Eirini Kaldelimu z CrowdHeritage a Datoptronu, Hugu Manguinhovi z Nadace Europeana a Uldisi Zariņšovi a Sanitě Reinsone z Lotyšské univerzity.
Vybrané reference
- Dokumentace poznámkových bloků Jupyter se řídí kritérii posuzování kvality projektů Jupyter institucemi GLAM, která byla zveřejněna v Candela, G., Chambers, S., & Sherratt, T. (2023). Přístup k posuzování kvality projektů Jupyter zveřejňovaných institucemi GLAM. Journal of the Association for Information Science and Technology (Sdružení pro informační vědu a technologie), 74(13), 1550–1564.
- Pilotní dokumentace README na GitHubu přejímá strukturu dokumentace datového souboru KU Leuven Libraries Git. Viz: KU Leuven Knihovny, oddělení digitalizace. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Version 01-beta2) [Soubor údajů]. Zenodo.
- M. Ziku, K. Zourou a A. Kouzelis, „AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow“, 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Benátky, Itálie, 7.–9. září 2026, v tisku.