
Continua a leggere per dare un'occhiata a un progetto pilota riproducibile che ha combinato l'uso della piattaforma e delle API di Europeana.eu, modelli di IA pre-formati, modellazione di codice in tempo reale e dati semantici, contributori umani su una piattaforma di crowdsourcing, uno strumento di thesaurus consapevole dei pregiudizi e metriche dei dati, che ha portato all'arricchimento di una collezione etnografica ucraina su Europeana.eu attraverso 55.000 azioni di annotazione e quasi 6.000 nuovi tag di metadati.
Tutela del patrimonio ucraino guidata dai cittadini
Dal 2025 Web2Learn, insieme alle università di Lussemburgo, Lettonia, Kiev Taras Shevchenko e alla Fondazione Europeana, collabora a AISTER, un progetto Erasmus+ che affronta la partecipazione dei cittadini abilitati all'IA nella salvaguardia del patrimonio culturale ucraino. Web2Learn contribuisce con la sua esperienza nell'innovazione guidata dai cittadini al progetto utilizzando tecnologie open source che promuovono l'istruzione, la formazione e la cittadinanza attiva.

HITL Crowdsourcing Pilot Poster di Web2Learn incorpora Folk Painting "Ritratto di una ragazza" come attribuito sopra, incorporato nella presente composizione con ulteriore permesso del titolare dei diritti.
Il consorzio AISTER ha previsto una serie di workshop con il coinvolgimento di ricercatori, studenti e giovani professionisti per tutta la durata del progetto. Cinque workshop guidati da Web2Learn online e in loco presso la Biblioteca dell'Università della Lettonia hanno offerto l'opportunità di condurre un progetto pilota: testare un flusso di lavoro "human-in-the-loop" per arricchire le collezioni digitali di immagini attraverso il crowdsourcing e gli strumenti di IA, invitando i partecipanti al seminario a interagire con il patrimonio etnografico ucraino e a diventare contributori attivi arricchendo e convalidando i tag descrittivi generati dall'IA.
Il progetto pilota è stato concepito come una risorsa aperta e riproducibile con una documentazione dettagliata per facilitare la ricerca e la formazione in ambito umanistico digitale ed è reso disponibile gratuitamente per il riutilizzo da parte di studiosi, studenti e insegnanti, nonché per il riutilizzo creativo.
Arte popolare ucraina su Europeana.eu
Nel 2025 il Krovets Online Museum of Traditional Art of Ukraine, che opera dal 2014 grazie agli sforzi volontari dei fondatori del museo, ha pubblicato una serie di dati su Europeana.eu attraverso l'aggregatore MUSEU, che comprende 3 840 manufatti del patrimonio etnografico, tra cui costumi tradizionali, mestieri tessili, arte popolare, cultura materiale e fotografie.
Le immagini utilizzate per il progetto pilota provengono da questa collezione etnografica. Nell'ambito del progetto pilota, una galleria di arte popolare ucraina è stata pubblicata su Europeana.eu, fornendo accesso alla sottocollezione di arte popolare del museo, che comprende 312 manufatti classificati come dipinti popolari o icone popolari. La maggior parte dei dipinti, raffiguranti la vita rurale quotidiana, il folklore e i temi religiosi, provengono dalle regioni etnografiche centrali dell'Ucraina, della Podniprovia centrale e della Poltavshchyna, e risalgono principalmente all'inizio e alla metà del XX secolo.
La collezione è composta principalmente da scene di genere, paesaggi e ritratti individuali. I dipinti popolari formano narrazioni visive, offrendo istantanee di paesaggi rurali, tradizioni religiose, motivi di arte popolare e cultura materiale quotidiana. Molti dei dettagli sono facili da notare quando si guardano le immagini, ma non sempre facili da scoprire attraverso la ricerca.
Il pilota di crowdsourcing human-in-the-loop
Il progetto pilota mirava a creare un nuovo livello di visibilità per l'arte popolare ucraina. Ha sviluppato un flusso di lavoro che combina l'uso di API Europeana, metodi basati sull'IA per l'elaborazione del linguaggio naturale e la visione artificiale, Jupyter Notebook come spazio di lavoro interattivo per la codifica riproducibile e l'elaborazione dei dati basata sull'etica, insieme all'impegno pubblico attraverso la piattaforma di crowdsourcing CrowdHeritage per creare tag descrittivi ricercabili, convalidati dall'uomo ed eticamente valutati in generale.
Per iniziare, sono state utilizzate due API di Europeana per recuperare gli elementi e i metadati della galleria, l'API del set di utenti di Europeana per accedere alle gallerie generate dagli utenti pubblicate su Europeana e l'API di ricerca di Europeana per il recupero dei metadati dei contenuti accessibili su Europeana, modellati utilizzando il modello di dati di Europeana (EDM). Quindi, sono state generate nuove annotazioni descrittive con strumenti di IA che hanno impiegato modelli e librerie di IA pre-addestrati open source nell'elaborazione del linguaggio naturale e nella visione artificiale. Le annotazioni automatizzate sono state generate in Jupyter Notebooks e serializzate in JSON-LD secondo il Web Annotation Data Model del W3C (World Wide Web Consortium), per supportare la loro importazione nella piattaforma di crowdsourcing CrowdHeritage gestita da Datoptron.
In totale, il progetto pilota ha sviluppato otto Jupyter Notebook, che funzionavano come ambienti informatici interattivi che consentono la codifica in tempo reale e la riproducibilità per supportare l'esecuzione end-to-end delle fasi di elaborazione dei dati. I notebook sono stati implementati in Google Colab per consentire la collaborazione e il co-editing in tempo reale e quindi trasferiti come repository aperto su GitHub per il controllo delle versioni, facilitando la trasparenza e la tracciabilità dell'ottimizzazione del codice collaborativo. Essi coprono l'intero processo di dati del progetto pilota in fasi sequenziali, che comprendono:
Fase 1: Generazione automatica di annotazioni da metadati testuali (basati su PNL)
1i. Recuperare gli ID degli elementi all'interno della galleria di arte popolare ucraina pubblicata utilizzando il set di utenti ΑPI di Europeana e recuperare i metadati testuali (ad esempio titoli, soggetti) degli artefatti utilizzando l'API di ricerca di Europeana.
1ii. Generare annotazioni automatizzate (tag di descrizione) dai metadati utilizzando tecniche di elaborazione del linguaggio naturale (NLP), in particolare euristiche basate su regole e Named Entity Recognition (NER) utilizzando la libreria open source Python spaCy.
Fase 2: Generazione automatica di annotazioni da immagini (basata sulla visione artificiale)
2i. Scarica gli artefatti della Galleria come immagini utilizzando l'API Europeana User Set.
2ii. Generare didascalie di immagini descrittive utilizzando tecniche di visione artificiale con modelli di IA pre-addestrati, in particolare varianti dei modelli Qwen open source: modello multimodale di linguaggio visivo (VLM) Qwen3-VL-2B-Instruct e modello di linguaggio grande (LLM) Qwen3.5-4B.
2iii. Genera annotazioni automatiche dalle didascalie delle immagini.
Fase 3: Preparazione di annotazioni automatizzate per la convalida crowdsourced (formattazione JSON-LD)
3i. Formattare tutte le annotazioni generate in base al modello di annotazione W3C per l'ingestione diretta nella piattaforma di crowdsourcing CrowdHeritage.
3ii. Converti le annotazioni finali formattate JSON in un CSV leggibile meccanicamente e combina tutte le annotazioni dei cinque workshop di crowdsourcing.
Fase 4: Garanzia della qualità dei dati e screening consapevole dei pregiudizi delle annotazioni convalidate dall'uomo
4i. Controllare le annotazioni finali contro termini dannosi, parziali o controversi nel vocabolario DE-BIAS attraverso l'interrogazione del thesaurus basato su RDF.
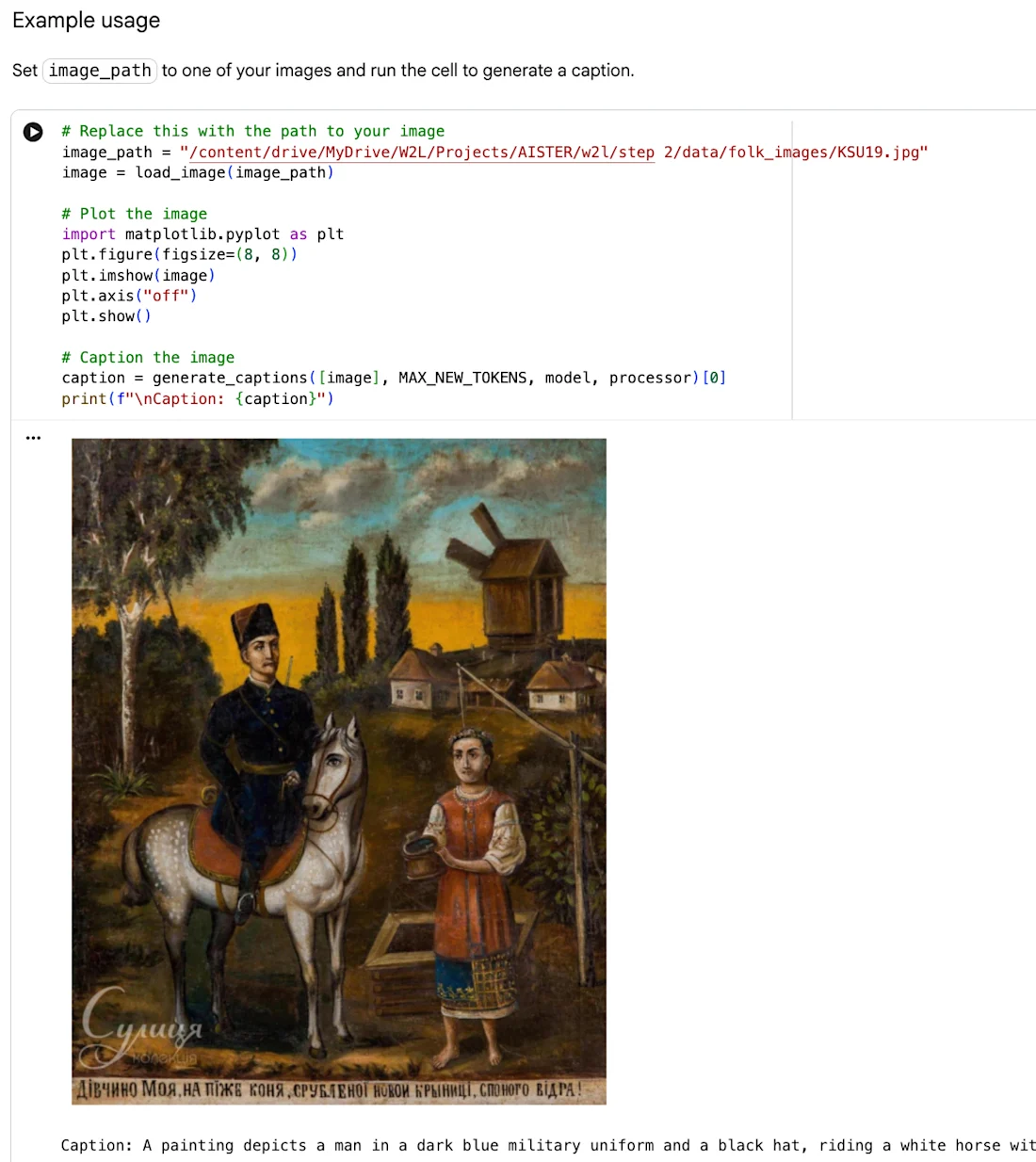
Nel corso di cinque workshop di crowdsourcing tenuti in loco e online, 70 partecipanti tra cui ricercatori, studenti universitari ed esperti di arte popolare hanno esaminato le annotazioni generate dall'IA, confermando tag accurati, rifiutando quelle fuorvianti attraverso upvotes e downvotes e contribuendo con ulteriori annotazioni proprie.
Approfondimenti sui dati e valutazione etica
La maggior parte delle immagini sono state arricchite con 15-20 nuovi tag descrittivi ciascuno. Complessivamente, sono state registrate quasi 55.000 azioni di annotazione, tra cui generazione di tag, upvotes e downvotes. Il risultato è l'apertura di percorsi più ricchi per scoprire e interagire con l'arte popolare ucraina. Le metriche post-campagna rivelano che la maggior parte delle annotazioni generate dall'IA sono state accettate come accurate, con solo poche respinte.
Questi cinque tag generati dall'IA hanno ricevuto i più alti tassi di accettazione:
- icona
- pittura
- uomo
- alberi
- donna.
Questi cinque tag generati dall'IA hanno ricevuto i più alti tassi di rifiuto:
- crepe
- usura
- danni
- piccolo oggetto
- personale.
L'applicazione di una valutazione d'impatto etico alle annotazioni finali è stata considerata un passo importante nel progetto pilota. È stato condotto un secondo livello di revisione per individuare il linguaggio potenzialmente problematico e rafforzare la responsabilità. Lo screening dei tag approvati dall'uomo contro il vocabolario DE-BIAS ha identificato un termine, schiavo, che è stato successivamente rivisto in persona schiava secondo la raccomandazione. Il vocabolario è stato applicato come misura di valutazione dell'impatto etico prima della pubblicazione finale dell'insieme di dati aperti, tenendo conto della raccomandazione dell'UNESCO sull'etica dell'intelligenza artificiale (2022) e dello strumento di valutazione dell'impatto etico (2023).
Lo sviluppo del progetto pilota e la comprensione delle sue dimensioni etiche legate all'IA sono stati anche informati dallo studio di analisi dei dati AISTER, che ha mappato 22 progetti di ricerca internazionali che utilizzano l'intelligenza artificiale e la partecipazione dei cittadini per la conservazione del patrimonio culturale in contesti di emergenza. Lo studio ha classificato i progetti selezionati utilizzando il quadro di classificazione AISTER, che offre una categorizzazione sistematica in 24 dimensioni analitiche progettate per analizzare le iniziative del patrimonio partecipativo basate sull'IA. Le dimensioni del quadro comprendono i domini del patrimonio culturale, il modello di partecipazione dei cittadini (Shirk et al., 2012) e il modello di cooperazione (Carayannis & Campbell, 2009), insieme alle dimensioni specifiche dell'IA, compresi i tipi di tecnologia di IA, il modello dell'agente razionale (Russell & Norvig, 2020, 4a ed.), la tipologia di IA etica applicata (Morley et al., 2019), i tipi di licenza e altro ancora. I dati approfonditi dello studio sono pubblicati sotto forma di visualizzazioni web interattive ad accesso aperto che offrono un'esplorazione comparativa del settore. Il flusso di lavoro pilota e i risultati sono pubblicati in un prossimo documento della conferenza (Ziku, Zourou, & Kouzelis, 2026).
Conclusioni
Il progetto pilota intendeva creare un percorso aperto e riproducibile per l'utilizzo degli strumenti di IA per elaborare i dati su larga scala, combinato con la partecipazione umana, la valutazione etica e le intuizioni sui dati, al fine di sostenere modi più accurati, responsabili, basati sulle metriche e arricchiti di scoprire l'arte popolare ucraina. A volte il viaggio fortuito nel patrimonio inizia con la parola digitata in una casella di ricerca. E a volte, le parole giuste possono portare alla luce una nuova collezione.
I tre contributori più attivi alla campagna di crowdsourcing hanno ricevuto rispettivamente un onorario e distintivi in oro, argento e bronzo: Inna Kaika, studentessa in lingua inglese e letteratura straniera, Mykola Gogol State University; Daria Markova, studentessa in Traduzione, Pryazovskyi State Technical University; Marko Lakhmatov, studente in Cybersecurity, Pryazovskyi State Technical University.
Riflettendo sulla sua partecipazione, Inna ha condiviso: "L'arte ucraina riflette la resilienza e la creatività della nostra gente e condividerla è più importante che mai. Spinto da questa passione, ho aderito alla campagna per rendere il patrimonio culturale più accessibile. Mi è piaciuto particolarmente il processo di annotazione e l'esplorazione della collezione etnografica. È stato un onore contribuire a un progetto che unisce arte e tecnologia."
Esplorare e riutilizzare le risorse pilota
Sei interessato ad applicare metodi simili alle tue collezioni?
- Guarda la campagna di crowdsourcing per l'arte popolare ucraina su CrowdHeritage.
- Esplora il pilota di crowdsourcing human-in-the-loop.
- Riutilizzare i notebook Jupyter open source, che documentano l'intero flusso di lavoro dal recupero dei dati alle annotazioni generate dall'IA e alle esportazioni pronte per la piattaforma.
- Accedere alle serie di dati aperte nell'archivio aperto di Zenodo, che comprendono i dati e gli output del progetto pilota per la conservazione, la citazione e il riutilizzo.
- Esplora le visualizzazioni interattive dei dati e scopri gli approfondimenti di 22 iniziative di ricerca internazionali che utilizzano l'IA e la partecipazione dei cittadini per la conservazione del patrimonio culturale in contesti di emergenza e oltre.
Riconoscimenti
Ringraziamo tutti i partner e collaboratori del progetto AISTER, in particolare Yevgen Dmytruk presso il Museo Krovets, Eirini Kaldeli presso CrowdHeritage e Datoptron, Hugo Manguinhas presso la Fondazione Europeana e Uldis Zariņš e Sanita Reinsone presso l'Università della Lettonia.
Riferimenti selezionati
- La documentazione dei Quaderni Jupyter segue i criteri di valutazione della qualità dei progetti Jupyter da parte delle istituzioni GLAM, pubblicati in Candela, G., Chambers, S., & Sherratt, T. (2023). Un approccio per valutare la qualità dei progetti Jupyter pubblicati dalle istituzioni GLAM. Gazzetta ufficiale dell'Associazione per la scienza e la tecnologia dell'informazione, 74(13), 1550-1564.
- La documentazione README del progetto pilota su GitHub adotta la struttura della documentazione della serie di dati basata su Git della KU Leuven Libraries. Cfr.: KU Leuven Libraries, dipartimento di digitalizzazione. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Versione 01-beta2) [Set di dati]. Zenodo.
- M. Ziku, K. Zourou, e A. Kouzelis, 'AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow", 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Venezia, Italia, 7-9 settembre 2026, in stampa.