
Olvasson tovább egy reprodukálható kísérleti projektről, amely ötvözte az Europeana.eu platform és az API-k használatát, az előre betanított MI-modelleket, az élő kódokat és a szemantikai adatmodellezést, az emberi közreműködőket egy közösségi kiszervezési platformon, egy elfogultságtudatos tezauruszeszközt és adatmérőket, ami az Europeana.eu-n található ukrán néprajzi gyűjtemény 55 000 annotációs művelettel és közel 6000 új metaadatcímkével való gazdagodásához vezetett.
Az ukrán örökség polgárok által vezetett védelme
2025 óta a Web2Learn – a luxemburgi, lett, kijevi egyetemekkel, Taras Shevchenkoval és az Europeana Alapítvánnyal együtt – együttműködik az AISTER-rel, egy Erasmus+ projekttel, amely a mesterséges intelligencián alapuló polgári részvétellel foglalkozik az ukrán kulturális örökség megőrzésében. A Web2Learn a polgárok által irányított innovációval kapcsolatos szakértelmével járul hozzá az oktatást, a képzést és az aktív polgári szerepvállalást elősegítő nyílt forráskódú technológiákat alkalmazó projekthez.

A Web2Learn HITL Crowdsourcing Pilot Plakátja tartalmazza a fent említett "Lányportré" című népfestményt, amelyet a jogtulajdonos további engedélyével építettek be a jelen kompozícióba.
Az AISTER-konzorcium a projekt időtartama alatt számos műhelytalálkozót tervezett kutatók, diákok és fiatal szakemberek részvételével. A Lett Egyetem könyvtárában a Web2Learn által online és a helyszínen vezetett öt workshop lehetőséget biztosított egy kísérleti projekt lebonyolítására: teszteljen egy „human-in-the-loop” munkafolyamatot a digitális képgyűjtemények közösségi kiszervezéssel és mesterségesintelligencia-eszközökkel történő gazdagítása érdekében, felkérve a műhely résztvevőit, hogy működjenek együtt az ukrán néprajzi örökséggel, és váljanak aktív közreműködőkké a mesterséges intelligencia által generált leíró címkék gazdagítása és validálása révén.
A kísérleti projektet nyílt és reprodukálható forrásként tervezték, részletes dokumentációval a digitális humán tudományok kutatásának és képzésének megkönnyítése érdekében, és szabadon hozzáférhetővé teszik a tudósok, diákok és tanárok számára újrafelhasználásra, valamint kreatív újrafelhasználásra.
Ukrán népművészet az Europeana.eu oldalon
2025-ben a múzeum alapítóinak önkéntes erőfeszítéseinek köszönhetően 2014 óta működő ukrán hagyományos művészetek online múzeuma (Krovets Online Museum of Traditional Art of Ukraine) a MUSEU aggregátoron keresztül adatkészletet tett közzé az Europeana.eu-n, amely 3840 néprajzi örökséghez tartozó műtárgyat tartalmaz, beleértve a hagyományos jelmezeket, a textilipari kézművességet, a népművészetet, az anyagkultúrát és a fényképeket.
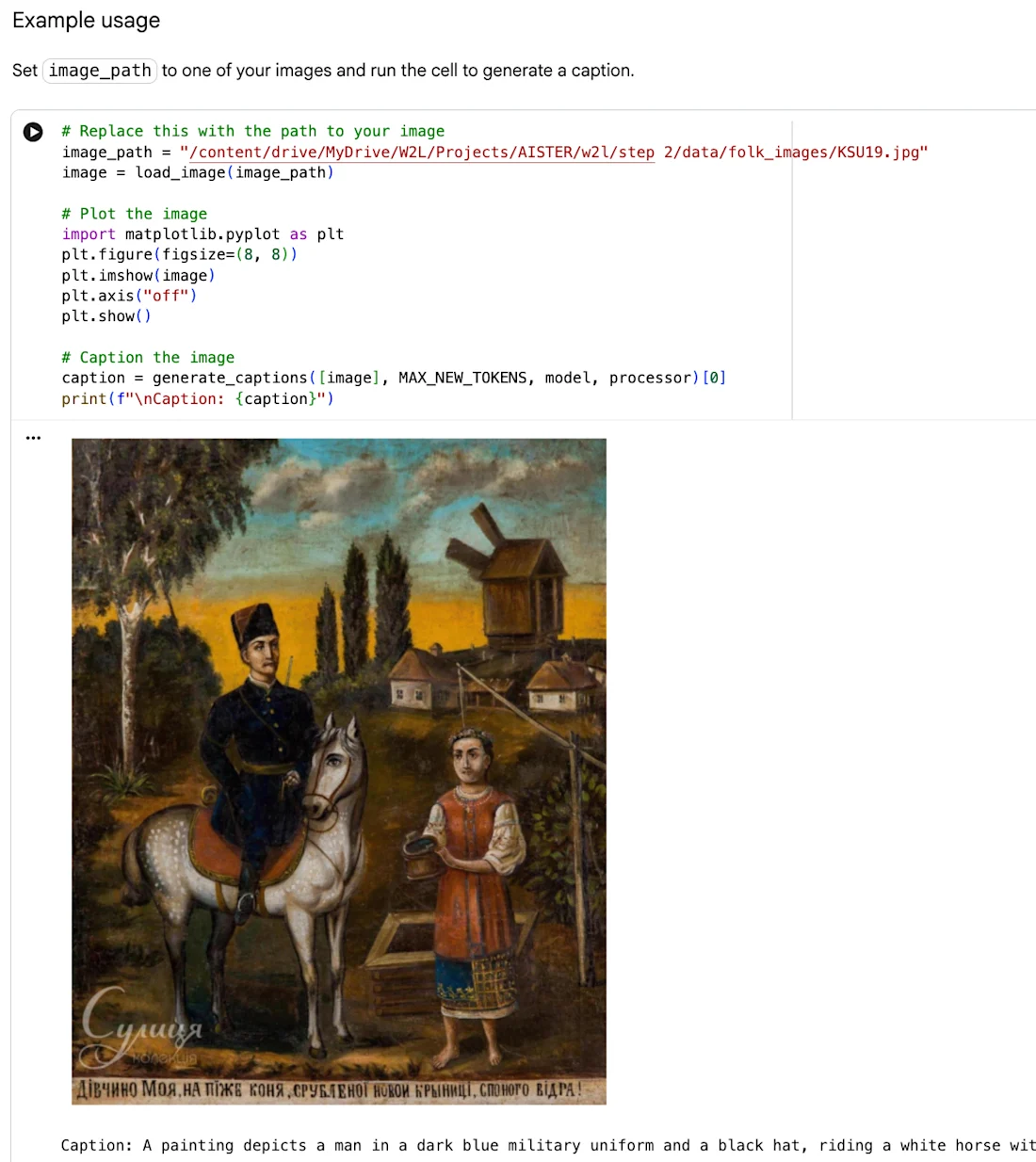
A pilothoz használt képek ebből a néprajzi gyűjteményből származnak. A kísérleti projekt részeként az Europeana.eu-n közzétették az ukrán népművészeti galériát, amely hozzáférést biztosít a múzeum népművészeti algyűjteményéhez, amely 312 népfestménynek vagy népi ikonnak minősülő műtárgyat tartalmaz. A legtöbb festmény, amely a mindennapi vidéki életet, a folklórt és a vallási témákat ábrázolja, Ukrajna, Közép-Podniprovia és Poltavshchyna központi néprajzi régióiból származik, és elsősorban a huszadik század elejére és közepére nyúlik vissza.
A gyűjtemény elsősorban műfaji jelenetekből, tájképekből és egyéni portrékból áll. A népi festmények vizuális narratívákat alkotnak, pillanatfelvételeket kínálnak a vidéki tájakról, a vallási hagyományokról, a népművészeti motívumokról és a mindennapi anyagi kultúráról. Sok részlet könnyen észrevehető a képek megtekintésekor, de nem mindig könnyű megtalálni a keresés során.
Az ember-in-the-loop crowdsourcing pilóta
A kísérleti projekt célja az volt, hogy új láthatósági réteget hozzon létre az ukrán népművészet számára. Olyan munkafolyamatot dolgozott ki, amely ötvözi az Europeana API-k, a természetes nyelvek feldolgozására és a számítógépes látásra szolgáló MI-alapú módszerek, a Jupyter Notebook mint a reprodukálható kódolás interaktív munkaterülete és az etikai alapú adatfeldolgozás használatát, valamint a CrowdHeritage crowdsourcing platformon keresztüli nyilvános szerepvállalást a kereshető, ember által hitelesített és etikailag értékelt leírási címkék létrehozása érdekében.
A kezdéshez két Europeana API-t használtak a galériaelemek és metaadatok letöltéséhez, az Europeana User Set API-t a felhasználók által létrehozott, az Europeanán közzétett galériákhoz való hozzáféréshez, valamint az Europeana Data Model (EDM) segítségével modellezett Europeana Search API-t az Europeanán elért tartalmak metaadat-visszakereséséhez. Ezután új leíró jegyzeteket hoztak létre olyan MI-eszközökkel, amelyek nyílt forráskódú, előre képzett MI-modelleket és könyvtárakat alkalmaztak a természetes nyelvi feldolgozásban és a számítógépes látásban. Az automatizált annotációk Jupyter Notebooks-ban készültek, és a W3C (World Wide Web Consortium) webes annotációs adatmodellje szerint JSON-LD-ben kerültek sorba, hogy támogassák a Datoptron által fenntartott CrowdHeritage crowdsourcing platformba való importálásukat.
A kísérleti projekt összesen nyolc Jupyter Notebookot fejlesztett ki, amelyek interaktív számítástechnikai környezetként működtek, amelyek lehetővé teszik az élő kódolást és a reprodukálhatóságot az adatfeldolgozási lépések végponttól végpontig történő végrehajtásának támogatása érdekében. A jegyzetfüzeteket a Google Colabban implementálták, hogy lehetővé tegyék a valós idejű együttműködést és a közös szerkesztést, majd a GitHub nyílt adattáraként átadták a verzióellenőrzéshez, megkönnyítve az együttműködési kód optimalizálásának átláthatóságát és nyomon követhetőségét. Ezek egymást követő lépésekben lefedik a kísérleti projekt teljes adatfolyamatát, amelyek a következőket foglalják magukban:
lépés: Automatizált annotáció generálás szöveges metaadatokból (NLP-alapú)
1i. A közzétett ukrán népművészeti galériában található tárgyak azonosítóinak lekérdezése az Europeana API felhasználói készlet segítségével, valamint a műtárgyak szöveges metaadatainak (pl. címek, tárgyak) lekérése az Europeana kereső API használatával.
1ii. Automatizált annotációk (leíró címkék) generálása a metaadatokból természetes nyelvi feldolgozási (NLP) technikákkal, különösen szabályalapú heurisztikával és elnevezett entitás felismeréssel (NER) a nyílt forráskódú Python könyvtár spaCy használatával.
lépés: Automatizált annotáció generálás képekből (számítógépes látás alapú)
2i. Töltse le képként a galéria műalkotásait az Europeana User Set API használatával.
ii. Leíró képaláírások generálása számítógépes látástechnikákkal, előre betanított MI-modellekkel, különösen a nyílt forráskódú Qwen-modellek változataival – Qwen3-VL-2B-Instruct multimodális vizuális nyelvi modell (VLM) és Qwen3.5-4B nagy nyelvi modell (LLM).
2iii. Automatikus jegyzetek generálása a képfeliratokból.
lépés: Automatizált annotációk készítése a crowdsourced validáláshoz (JSON-LD formázás)
3i. Formázza az összes generált annotációt a W3C annotációs modell alapján a CrowdHeritage crowdsourcing platformon történő közvetlen lenyeléshez.
3ii. A JSON-formátumú végleges annotációkat alakítsa át géppel olvasható CSV-vé, és kombinálja az öt crowdsourcing workshop összes annotációját.
lépés: Az ember által hitelesített megjegyzések adatminőség-biztosítása és elfogultság-tudatos szűrése
4i. Ellenőrizze a végleges annotációkat a DE-BIAS szótár káros, elfogult vagy vitatott kifejezéseivel szemben az RDF-alapú tezaurusz lekérdezésen keresztül.
A helyszínen és online tartott öt crowdsourcing workshop során 70 résztvevő, köztük kutatók, egyetemi hallgatók és népművészeti szakértők áttekintették a mesterséges intelligencia által generált annotációkat, pontos címkéket erősítettek meg, elutasították a félrevezető címkéket felfelé és lefelé irányuló szavazatokkal, és további saját annotációkkal járultak hozzá.
Adatbetekintés és etikai értékelés
A képek többsége 15-20 új leíró címkével gazdagodott. Összességében közel 55 000 annotációs műveletet rögzítettek, beleértve a címkegenerálást, az upvote-okat és a downvotes-okat. Az eredmény gazdagabb utakat nyit meg az ukrán népművészet felfedezéséhez és az azzal való kapcsolatfelvételhez. A kampány utáni mérőszámok azt mutatják, hogy a mesterséges intelligencia által generált annotációk többségét pontosnak fogadták el, és csak néhányat utasítottak el.
Ez az öt mesterséges intelligencia által generált címke kapta a legmagasabb elfogadási arányt:
- ikon
- festés
- férfi
- fák
- egy nő.
Ez az öt mesterséges intelligencia által generált címke kapta a legmagasabb elutasítási arányt:
- repedések
- viselni
- sérülés
- kis tárgy
- személyzet.
Az etikai hatásvizsgálatnak a végleges magyarázó jegyzetekre való alkalmazását a kísérleti projekt fontos lépéseként kezelték. A felülvizsgálat második rétegét a potenciálisan problémás nyelvezet azonosítása és az elszámoltathatóság megerősítése érdekében végezték el. Az ember által jóváhagyott címkéknek a DE-BIAS szókincs alapján történő szűrése egy kifejezést azonosított, a rabszolgát, amelyet később az ajánlás szerint rabszolgává tettek. A szókincset etikai hatásvizsgálati intézkedésként alkalmazták a végleges nyílt adatkészlet közzététele előtt, figyelembe véve az UNESCO „Ajánlás a mesterséges intelligencia etikájáról” című ajánlását (2022) és az „Etikai hatásvizsgálat” eszközt (2023).
A kísérleti projekt kidolgozását és a mesterséges intelligenciával kapcsolatos etikai dimenzióinak megértését az AISTER adatelemzési tanulmánya is segítette, amely 22 olyan nemzetközi kutatási projektet térképezett fel, amelyek vészhelyzetekben mesterséges intelligenciát és polgári részvételt használnak a kulturális örökség megőrzése érdekében. A tanulmány a kiválasztott projekteket az AISTER osztályozási keret felhasználásával osztályozta, amely szisztematikus kategorizálást kínál 24 elemzési dimenzió között, amelyek célja a mesterséges intelligencián alapuló, részvételi örökséggel kapcsolatos kezdeményezések elemzése. A keretdimenziók magukban foglalják a kulturális örökség területeit, a polgári részvételi modellt (Shirk et al., 2012) és az együttműködési modellt (Carayannis & Campbell, 2009), az MI-specifikus dimenziók mellett, beleértve az MI-technológiatípusokat, a racionális ágensmodellt (Russell & Norvig, 2020, 4. kiadás), az alkalmazott etikai MI-tipológiát (Morley et al., 2019), az engedélytípusokat és így tovább. A tanulmány adatmegtekintéseit nyílt hozzáférésű interaktív webes vizualizációk formájában teszik közzé, amelyek a terület összehasonlító feltárását kínálják. A kísérleti munkafolyamatot és az eredményeket egy soron következő konferenciadokumentumban teszik közzé (Ziku, Zourou, & Kouzelis, 2026).
Következtetések
A kísérleti projekt célja az volt, hogy nyílt és reprodukálható útvonalat hozzon létre a mesterségesintelligencia-eszközöknek az adatok nagy léptékű feldolgozására való használatához, az emberi részvétellel, az etikai értékeléssel és az adatokba való betekintéssel kombinálva, hogy támogassa az ukrán népművészet felfedezésének pontosabb, elszámoltathatóbb, mérőszámokon alapuló és gazdagabb módjait. Néha az örökségbe való rendhagyó utazás a keresőmezőbe beírt szóval kezdődik. És néha a megfelelő szavak új gyűjteményt hozhatnak napvilágra.
A crowdsourcing kampány három legaktívabb résztvevője tiszteletdíjat, valamint arany-, ezüst- és bronzjelvényeket kapott: Inna Kaika, angol nyelv és idegen irodalom szakos hallgató, Mykola Gogol Állami Egyetem; Daria Markova, fordítás szakos hallgató, Pryazovskyi Állami Műszaki Egyetem; Marko Lakhmatov, kiberbiztonsági hallgató, Pryazovskyi Állami Műszaki Egyetem.
Részvételéről elmélkedve Inna elmondta: „Az ukrán művészet tükrözi népünk rezilienciáját és kreativitását, és megosztásuk fontosabb, mint valaha. E szenvedélytől vezérelve csatlakoztam a kulturális örökség hozzáférhetőbbé tételét célzó kampányhoz. Különösen élveztem az annotációs folyamatot és a néprajzi gyűjtemény feltárását. Megtiszteltetés volt hozzájárulni egy olyan projekthez, amely összefogja a művészetet és a technológiát.”
A kísérleti erőforrások feltárása és újrafelhasználása
Érdekli, hogy hasonló módszereket alkalmazzon a saját gyűjteményeire?
- Tekintse meg az ukrán népművészet crowdsourcing kampányát a CrowdHeritage-en.
- Fedezze fel a „human-in-the-loop” crowdsourcing pilotot.
- Használja újra a nyílt forráskódú Jupyter notebookokat, amelyek dokumentálják a teljes munkafolyamatot az adatlehívástól a mesterséges intelligencia által generált annotációkig és a platformkész exportálásig.
- Hozzáférés a Zenodo nyílt adattárában található nyílt adatkészletekhez, amelyek megőrzés, hivatkozás és további felhasználás céljából magukban foglalják a kísérleti projekt adatait és kimeneteit.
- Fedezze fel az interaktív adatvizualizációkat, és fedezze fel 22 olyan nemzetközi kutatási kezdeményezés eredményeit, amelyek a mesterséges intelligenciát és a polgári részvételt használják a kulturális örökség megőrzésére vészhelyzetekben és azon túl.
Elismerések
Szeretnénk köszönetet mondani az AISTER projekt valamennyi partnerének és munkatársának, különösen Yevgen Dmytruk-nak a Krovets Múzeumban, Eirini Kaldeli-nek a CrowdHeritage-ben és Datoptron-ban, Hugo Manguinhas-nak az Europeana Alapítványban, valamint Uldis Zariņš-nak és Sanita Reinsone-nak a Lett Egyetemen.
Válogatott referenciák
- A Jupyter Notebooks dokumentációja a GLAM-intézmények Jupyter-projektekre vonatkozó minőségértékelési kritériumait követi, amelyeket Candela, G., Chambers, S., & Sherratt, T. (2023) tett közzé. A GLAM-intézmények által közzétett Jupyter-projektek minőségének értékelésére szolgáló megközelítés. Journal of the Association for Information Science and Technology, 74(13), 1550–1564. o.
- A kísérleti projekt GitHub-ra vonatkozó README-dokumentációja átveszi a KU Leuven Libraries Git-alapú adatkészlet-dokumentációjának szerkezetét. Lásd: KU Leuven Libraries, Digitalizációs Osztály. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Version 01-beta2) [Adatkészlet]. Zenodo vagyok.
- M. Ziku, K. Zourou és A. Kouzelis, „AI-asszisztált metaadatok gazdagítása a néprajzi örökségért: A Reproducible Human-in-the-Loop Crowdsourcing Workflow, 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Velence, Olaszország, 2026. szeptember 7–9., sajtóban.