
Läs vidare för en inblick i en reproducerbar pilot som kombinerade användningen av Europeana.eu-plattformen och API:er, förtränade AI-modeller, live-kod och semantisk datamodellering, mänskliga bidragsgivare på en crowdsourcing-plattform, ett biasmedvetet tesaurusverktyg och datamått, vilket ledde till berikningen av en ukrainsk etnografisk samling på Europeana.eu genom 55 000 annoteringsåtgärder och nästan 6 000 nya metadatataggar.
Medborgarstyrt skydd av det ukrainska kulturarvet
Sedan 2025 har Web2Learn – tillsammans med universiteten i Luxemburg, Lettland, Kiev Taras Shevchenko och Europeana Foundation – samarbetat om AISTER, ett Erasmus+-projekt som tar itu med AI-baserat medborgardeltagande för att skydda Ukrainas kulturarv. Web2Learn bidrar med sin expertis inom medborgardriven innovation till projektet med hjälp av teknik med öppen källkod som främjar utbildning och aktivt medborgarskap.

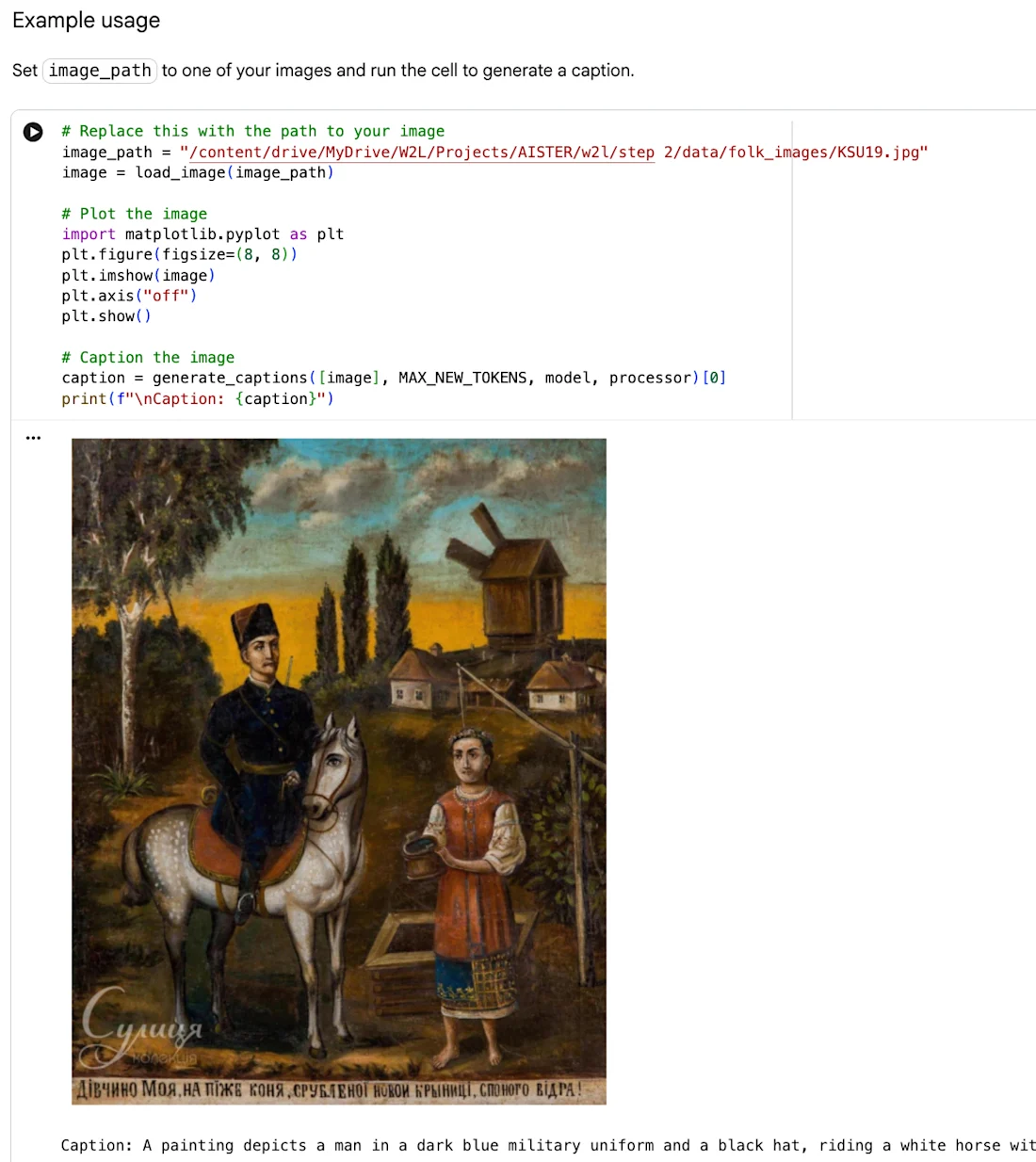
HITL Crowdsourcing Pilot Poster av Web2Learn innehåller folkmålning "Porträtt av en flicka" som tillskrivs ovan, införlivad i den nuvarande kompositionen med ytterligare tillstånd från rättighetsinnehavaren.
AISTER-konsortiet har planerat en rad workshoppar med deltagande av forskare, studenter och unga yrkesverksamma under projektets löptid. Fem workshoppar som leddes av Web2Learn online och på plats vid Lettlands universitets bibliotek gav möjlighet att driva ett pilotprojekt: testa ett mänskligt arbetsflöde för att berika digitala samlingar av bilder genom crowdsourcing och AI-verktyg, bjuda in workshopdeltagarna att samarbeta med Ukrainas etnografiska arv och bli aktiva bidragsgivare genom att berika och validera AI-genererade beskrivningstaggar.
Pilotprojektet utformades som en öppen och reproducerbar resurs med detaljerad dokumentation för att underlätta forskning och utbildning inom digital humaniora, och görs fritt tillgängligt för vidareutnyttjande av forskare, studenter och lärare samt för kreativ återanvändning.
Ukrainsk folkkonst på Europeana.eu
År 2025 offentliggjorde Krovets Online Museum of Traditional Art of Ukraine, som har varit i drift sedan 2014 tack vare frivilliga insatser från museets grundare, ett dataset på Europeana.eu genom aggregatorn MUSEU, som omfattar 3 840 artefakter av etnografiskt arv, inbegripet traditionella dräkter, textilhantverk, folkkonst, materiell kultur och fotografier.
De bilder som används för piloten kommer från denna etnografiska samling. Som en del av pilotprojektet publicerades ett galleri med ukrainsk folkkonst på Europeana.eu, som ger tillgång till museets undersamling av folkkonst, som omfattar 312 artefakter som klassificeras som folkmålningar eller folkikoner. De flesta målningar, som skildrar vardagslivet på landsbygden, folklore och religiösa teman, härstammar från de centrala etnografiska regionerna i Ukraina, Mellersta Podniprovien och Poltavshchyna, och dateras främst till början och mitten av nittonhundratalet.
Samlingen består främst av genrescener, landskap och individuella porträtt. Folkmålningarna bildar visuella berättelser och erbjuder ögonblicksbilder av landsbygdslandskap, religiösa traditioner, folkkonstmotiv och vardaglig materiell kultur. Många av detaljerna är lätta att märka när man tittar på bilderna, men inte alltid lätt att upptäcka genom sökning.
Human-in-the-loop-piloten för crowdsourcing
Pilotprojektet syftade till att skapa ett nytt lager av synlighet för ukrainsk folkkonst. Det utvecklade ett arbetsflöde som kombinerar användningen av Europeanas API:er, AI-baserade metoder för bearbetning av naturligt språk och datorseende, Jupyter Notebook som en interaktiv arbetsyta för reproducerbar kodning och etikbaserad databehandling, tillsammans med allmänhetens engagemang via crowdsourcingplattformen CrowdHeritage för att skapa sökbara, människovaliderade och etiskt bedömda beskrivningstaggar i stort.
För att komma igång användes två Europeana API:er för att hämta galleriobjekt och metadata, Europeana User Set API för åtkomst till användargenererade gallerier som publicerats på Europeana och Europeana Search API för metadatahämtning av innehåll som hämtats på Europeana, modellerat med hjälp av Europeana Data Model (EDM). Därefter genererades nya beskrivande kommentarer med AI-verktyg som använde förtränade AI-modeller och bibliotek med öppen källkod i naturlig språkbehandling och datorseende. De automatiserade anteckningarna genererades i Jupyter Notebooks och serialiserades i JSON-LD enligt W3C:s webbanteckningsdatamodell (World Wide Web Consortium) för att stödja deras import till CrowdHeritage crowdsourcing-plattformen som underhålls av Datoptron.
Totalt utvecklade piloten åtta Jupyter Notebooks, som fungerade som interaktiva datormiljöer som möjliggör live-kodning och reproducerbarhet för att stödja end-to-end-exekveringen av databehandlingsstegen. Anteckningsböckerna implementerades i Google Colab för att möjliggöra samarbete och samredigering i realtid och överfördes sedan som ett öppet arkiv på GitHub för versionskontroll, vilket underlättar transparens och spårbarhet för kollaborativ kodoptimering. De omfattar pilotens fullständiga dataprocess i sekventiella steg, som omfattar följande:
Steg 1: Automatiserad anteckningsgenerering från textmetadata (NLP-baserad)
1i. Hämta objekt-ID:n i det publicerade galleriet för ukrainsk folkkonst med hjälp av Europeanas användaruppsättning ΑPI och hämta textmetadata (t.ex. titlar, ämnen) för artefakterna med hjälp av Europeanas sök-API.
1ii. Generera automatiska anteckningar (beskrivningstaggar) från metadata med hjälp av tekniker för bearbetning av naturligt språk (NLP), särskilt regelbaserad heuristik och igenkänning av namngivna enheter (NER) med hjälp av Python-biblioteket spaCy med öppen källkod.
Steg 2: Automatiserad anteckningsgenerering från bilder (datorvisionsbaserad)
2i. Ladda ner galleriartefakter som bilder med hjälp av Europeanas API för användaruppsättningar.
2ii. Generera beskrivande bildtexter med hjälp av datorseendetekniker med förtränade AI-modeller, särskilt varianter av Qwen-modellerna med öppen källkod – Qwen3-VL-2B-Instruct multimodal visual language model (VLM) och Qwen3.5-4B large language model (LLM).
2iii. Generera automatiska anteckningar från bildtexterna.
Steg 3: Utarbetande av automatiska anteckningar för crowdsourced validering (JSON-LD-formatering)
3i. Formatera alla genererade anteckningar baserat på W3C-anteckningsmodellen för direkt intag i crowdsourcing-plattformen CrowdHeritage.
3ii. Konvertera de JSON-formaterade slutliga anteckningarna till en maskinläsbar CSV och kombinera alla anteckningar från de fem crowdsourcing-verkstäderna.
Steg 4: Kvalitetssäkring av data och systematisk screening av mänskligt validerade anteckningar
4i. Kontrollera slutliga kommentarer mot skadliga, partiska eller omtvistade termer i DE-BIAS-ordlistan genom RDF-baserade tesaurusförfrågningar.
Under fem crowdsourcing-workshoppar som hölls på plats och online granskade 70 deltagare, inklusive forskare, universitetsstudenter och folkkonstexperter, AI-genererade anteckningar, bekräftade korrekta taggar, avvisade vilseledande genom uppröstningar och nedröstningar och bidrog med ytterligare egna kommentarer.
Datainsikter och etisk bedömning
Majoriteten av bilderna berikades med 15 till 20 nya beskrivande taggar vardera. Totalt registrerades nästan 55 000 annoteringsåtgärder, inklusive tagggenerering, uppröstningar och nedröstningar. Resultatet öppnar rikare vägar för att upptäcka och engagera sig i ukrainsk folkkonst. Mätningarna efter kampanjen visar att de flesta AI-genererade anteckningar accepterades som korrekta, och endast ett fåtal avvisades.
Dessa fem AI-genererade taggar fick den högsta acceptansen:
- ikon
- målning
- man
- träd
- kvinna.
Dessa fem AI-genererade taggar fick de högsta avslagsfrekvenserna:
- sprickor
- bära
- skada
- litet föremål
- personal.
Att tillämpa en etisk konsekvensbedömning på de slutliga kommentarerna behandlades som ett viktigt steg i piloten. Ett andra granskningsskikt genomfördes för att identifiera potentiellt problematiskt språk och stärka ansvarsskyldigheten. Screening av de mänskligt godkända taggarna mot DE-BIAS Vocabulary identifierade en term, slav, som senare reviderades till förslavad person enligt rekommendationen. Ordförrådet tillämpades som en etisk konsekvensbedömningsåtgärd före den slutliga publiceringen av öppna dataset, med beaktande av Unescos rekommendation om etik inom artificiell intelligens (2022) och verktyget för etisk konsekvensbedömning (2023).
Utvecklingen av pilotprojektet och förståelsen av dess AI-relaterade etiska dimensioner baserades också på AISTER-dataanalysstudien, som kartlade 22 internationella forskningsprojekt som använder artificiell intelligens och medborgardeltagande för bevarande av kulturarvet i nödsituationer. I studien klassificerades de utvalda projekten med hjälp av AISTER-klassificeringsramen, som erbjuder en systematisk kategorisering över 24 analytiska dimensioner som utformats för att analysera AI-drivna deltagande kulturarvsinitiativ. Ramdimensionerna omfattar kulturarvsområden, modellen för medborgardeltagande (Shirk m.fl., 2012) och samarbetsmodellen (Carayannis & Campbell, 2009), tillsammans med AI-specifika dimensioner, inklusive AI-tekniktyper, modellen för rationella agenter (Russell & Norvig, 2020, fjärde upplagan), den tillämpade etiska AI-typologin (Morley m.fl., 2019), licenstyper med mera. Studiens datainsikter publiceras som interaktiva webbvisualiseringar med öppen åtkomst som erbjuder en jämförande undersökning av området. Pilotarbetsflödet och resultaten publiceras i ett kommande konferensdokument (Ziku, Zourou, & Kouzelis, 2026).
Slutsatser
Pilotprojektet syftade till att skapa en öppen och reproducerbar väg för att använda AI-verktyg för att behandla data i stor skala, i kombination med mänskligt deltagande, etisk bedömning och datainsikter, för att stödja mer exakta, ansvarsfulla, mätdrivna och berikade sätt att upptäcka ukrainsk folkkonst. Ibland börjar den serendipitösa resan in i arvet med ordet skrivs in i en sökruta. Och ibland kan de rätta orden ge en ny samling till ljus.
De tre mest aktiva bidragsgivarna till crowdsourcing-kampanjen fick ett honorarium samt guld-, silver- och bronsmärken respektive: Inna Kaika, student i engelska språket och utländsk litteratur, Mykola Gogol State University; Daria Markova, student i översättning, Pryazovskyi State Technical University; Marko Lakhmatov, student i cybersäkerhet, Pryazovskyi State Technical University.
Inna reflekterade över sitt deltagande och delade med sig av följande: ”Ukrainsk konst återspeglar vårt folks motståndskraft och kreativitet, och det är viktigare än någonsin att dela med sig av den. Drivna av denna passion gick jag med i kampanjen för att göra kulturarvet mer tillgängligt. Jag njöt särskilt av annoteringsprocessen och utforskningen av den etnografiska samlingen. Det var en ära att få bidra till ett projekt som sammanför konst och teknik.”
Utforska och återanvänd pilotresurserna
Intresserad av att tillämpa liknande metoder på dina egna samlingar?
- Se crowdsourcingkampanjen för ukrainsk folkkonst på CrowdHeritage.
- Utforska piloten för crowdsourcing med människor i kretsloppet.
- Återanvänd Jupyter Notebooks med öppen källkod, som dokumenterar hela arbetsflödet från datahämtning till AI-genererade anteckningar och plattformsklar export.
- Få tillgång till de öppna dataseten i Zenodos öppna databas, som omfattar pilotens data och utdata för bevarande, citering och återanvändning.
- Utforska interaktiva datavisualiseringar och upptäck insikter från 22 internationella forskningsinitiativ som använder AI och medborgardeltagande för att bevara kulturarvet i och utanför nödsituationer.
Bekräftelser
Vi vill tacka alla AISTER-projektpartner och samarbetspartners, särskilt Yevgen Dmytruk vid Krovets Museum, Eirini Kaldeli vid CrowdHeritage och Datoptron, Hugo Manguinhas vid Europeana Foundation och Uldis Zariņš och Sanita Reinsone vid Lettlands universitet.
Valda referenser
- Dokumentationen av Jupyter Notebooks följer kriterierna för kvalitetsbedömning för Jupyter-projekt av GLAM-institutioner, som publicerades i Candela, G., Chambers, S., & Sherratt, T. (2023). En metod för att bedöma kvaliteten på Jupyter-projekt som offentliggörs av GLAM-institutioner. Tidskrift för Association for Information Science and Technology, 74(13), 1550–1564.
- Pilotens README-dokumentation om GitHub antar strukturen för KU Leuven Libraries Git-baserade datasetdokumentation. Se följande: KU Leuvens bibliotek, digitaliseringsavdelningen. (2019). Datasetet Porträttsamling för KU Leuvens bibliotek, Specialsamlingar (version 01-beta2) [Dataset]. Zenodo.
- M. Ziku, K. Zourou och A. Kouzelis, "AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow, 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Venedig, Italien, 7–9 september 2026, i pressen.