
Lesen Sie weiter, um einen Einblick in ein reproduzierbares Pilotprojekt zu erhalten, das die Nutzung der Europeana.eu-Plattform und APIs, vortrainierte KI-Modelle, Live-Code und semantische Datenmodellierung, menschliche Mitwirkende auf einer Crowdsourcing-Plattform, ein voreingenommenes Thesaurus-Tool und Datenmetriken kombinierte, was zur Bereicherung einer ukrainischen ethnografischen Sammlung auf Europeana.eu durch 55.000 Anmerkungsaktionen und fast 6.000 neue Metadaten-Tags führte.
Bürgergeführter Schutz des ukrainischen Erbes
Seit 2025 arbeitet Web2Learn – gemeinsam mit den Universitäten Luxemburg, Lettland, Kiew Taras Shevchenko und der Europeana Foundation – an AISTER, einem Erasmus+-Projekt, das sich mit der KI-gestützten Bürgerbeteiligung am Schutz des ukrainischen Kulturerbes befasst. Web2Learn bringt seine Expertise in bürgerorientierten Innovationen in das Projekt ein, indem es Open-Source-Technologien einsetzt, die Bildung, Ausbildung und aktive Bürgerschaft fördern.

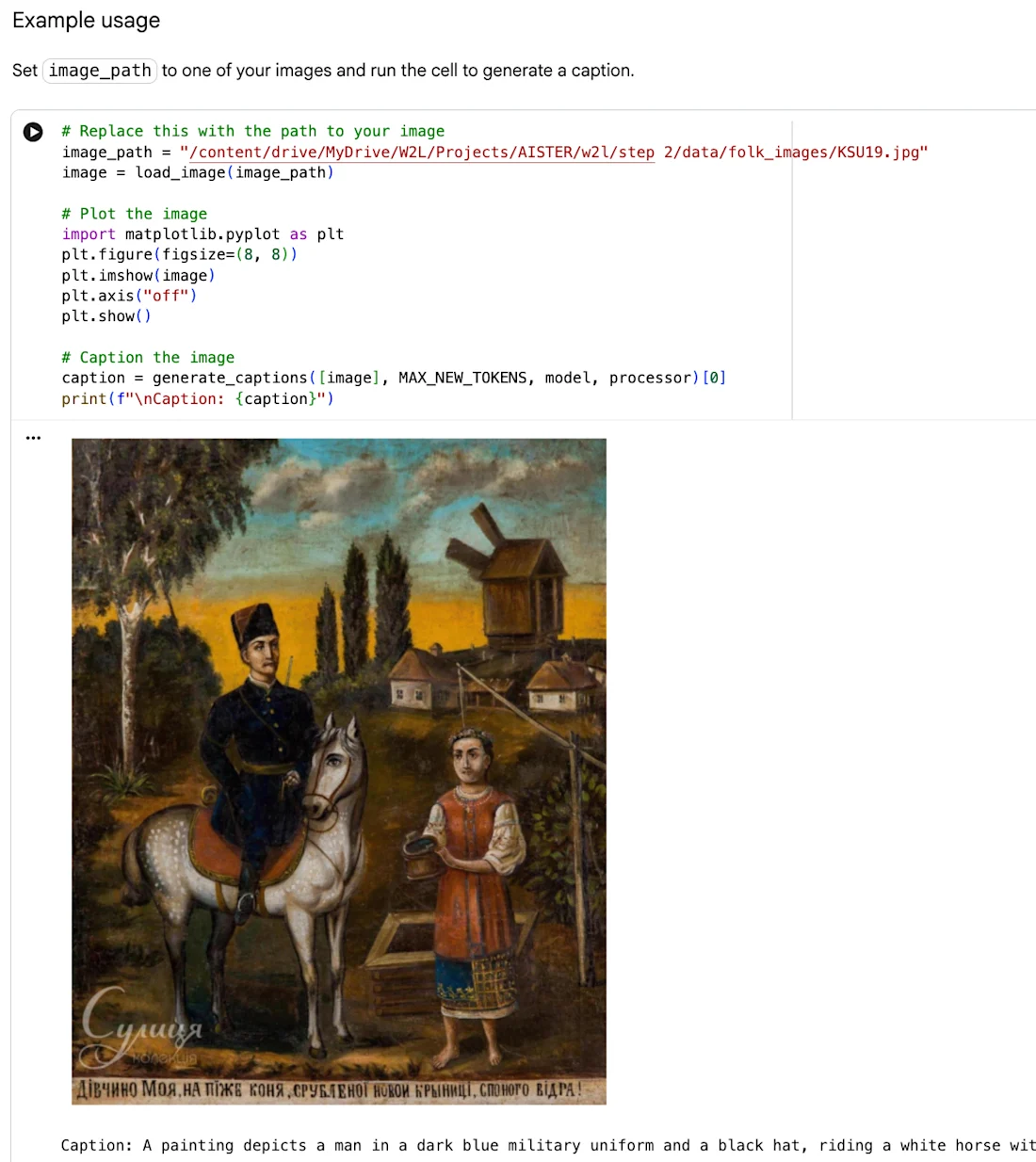
HITL Crowdsourcing Pilot Poster von Web2Learn enthält Folk Painting "Porträt eines Mädchens" wie oben zugeschrieben, in die vorliegende Komposition mit zusätzlicher Genehmigung des Rechteinhabers aufgenommen.
Das AISTER-Konsortium hat eine Reihe von Workshops unter Beteiligung von Forschern, Studenten und jungen Fachleuten für die Dauer des Projekts ins Auge gefasst. Fünf Workshops unter der Leitung von Web2Learn online und vor Ort in der Bibliothek der Universität Lettland boten die Möglichkeit, ein Pilotprojekt durchzuführen: Testen Sie einen Human-in-the-Loop-Workflow, um digitale Bildersammlungen durch Crowdsourcing- und KI-Tools zu bereichern, und laden Sie die Workshop-Teilnehmer ein, sich mit dem ukrainischen ethnografischen Erbe zu beschäftigen und aktiv mitzuwirken, indem Sie KI-generierte Beschreibungs-Tags bereichern und validieren.
Das Pilotprojekt wurde als offene und reproduzierbare Ressource mit detaillierter Dokumentation konzipiert, um die digitale geisteswissenschaftliche Forschung und Ausbildung zu erleichtern, und wird von Wissenschaftlern, Studenten und Lehrern zur Wiederverwendung sowie zur kreativen Wiederverwendung zur Verfügung gestellt.
Ukrainische Volkskunst auf Europeana.eu
Im Jahr 2025 veröffentlichte das Krovets Online Museum of Traditional Art of Ukraine, das seit 2014 dank der freiwilligen Bemühungen der Museumsgründer tätig ist, über den Aggregator MUSEU einen Datensatz auf Europeana.eu, der 3.840 Artefakte des ethnografischen Erbes umfasst, darunter Trachten, Textilhandwerk, Volkskunst, materielle Kultur und Fotografien.
Die für den Piloten verwendeten Bilder stammen aus dieser ethnographischen Sammlung. Im Rahmen des Pilotprojekts wurde auf Europeana.eu eine Galerie der ukrainischen Volkskunst veröffentlicht, die Zugang zur Untersammlung der Volkskunst des Museums bietet, die 312 Artefakte umfasst, die als Volksgemälde oder Volksikonen eingestuft sind. Die meisten Gemälde, die den ländlichen Alltag, Folklore und religiöse Themen darstellen, stammen aus den zentralen ethnographischen Regionen der Ukraine, Mittelpodniprovia und Poltavshchyna und stammen hauptsächlich aus dem frühen und mittleren 20. Jahrhundert.
Die Sammlung setzt sich in erster Linie aus Genreszenen, Landschaften und Einzelporträts zusammen. Die Volksbilder bilden visuelle Erzählungen und bieten Schnappschüsse von ländlichen Landschaften, religiösen Traditionen, Volkskunstmotiven und alltäglicher materieller Kultur. Viele der Details sind beim Betrachten der Bilder leicht zu erkennen, aber nicht immer leicht durch die Suche zu entdecken.
Der Human-in-the-Loop-Crowdsourcing-Pilot
Das Pilotprojekt zielte darauf ab, eine neue Sichtbarkeitsebene für die ukrainische Volkskunst zu schaffen. Es entwickelte einen Workflow, der die Verwendung von Europeana-APIs, KI-basierte Methoden für die Verarbeitung natürlicher Sprache und Computer Vision, Jupyter Notebook als interaktiven Arbeitsbereich für reproduzierbare Codierung und ethisch basierte Datenverarbeitung kombiniert, zusammen mit der öffentlichen Beteiligung über die Crowdsourcing-Plattform CrowdHeritage, um durchsuchbare, von Menschen validierte und ethisch bewertete Beschreibungs-Tags im Allgemeinen zu erstellen.
Zu Beginn wurden zwei Europeana APIs verwendet, um die Galerieelemente und Metadaten abzurufen, die Europeana User Set API für den Zugriff auf nutzergenerierte Galerien, die auf Europeana veröffentlicht wurden, und die Europeana Search API für den Metadatenabruf von Inhalten, auf die auf Europeana zugegriffen wurde, modelliert mit dem Europeana Data Model (EDM). Dann wurden neue beschreibende Anmerkungen mit KI-Tools generiert, die vortrainierte Open-Source-KI-Modelle und -Bibliotheken in der Verarbeitung natürlicher Sprache und Computer Vision verwendeten. Die automatisierten Anmerkungen wurden in Jupyter Notebooks generiert und in JSON-LD nach dem Web Annotation Data Model des W3C (World Wide Web Consortium) serialisiert, um ihren Import in die CrowdHeritage-Crowdsourcing-Plattform von Datoptron zu unterstützen.
Insgesamt entwickelte der Pilot acht Jupyter Notebooks, die als interaktive Computerumgebungen fungierten, die Live-Codierung und Reproduzierbarkeit ermöglichen, um die End-to-End-Ausführung der Datenverarbeitungsschritte zu unterstützen. Die Notebooks wurden in Google Colab implementiert, um Echtzeit-Zusammenarbeit und Co-Editing zu ermöglichen, und dann als offenes Repository auf GitHub zur Versionskontrolle übertragen, was die Transparenz und Rückverfolgbarkeit der kollaborativen Codeoptimierung erleichtert. Sie decken den gesamten Datenprozess des Piloten in aufeinanderfolgenden Schritten ab, darunter:
Schritt 1: Automatisierte Annotationsgenerierung aus textuellen Metadaten (NLP-basiert)
1i. Rufen Sie die Artikel-IDs in der veröffentlichten Galerie der ukrainischen Volkskunst mit dem Europeana User Set ΑPI ab und holen Sie Text-Metadaten (z. B. Titel, Themen) der Artefakte mit der Europeana Search API ab.
1ii. Generieren Sie automatisierte Anmerkungen (Description Tags) aus den Metadaten mit NLP-Techniken (Natural Language Processing), insbesondere regelbasierte Heuristiken und Named Entity Recognition (NER) mit der Open-Source-Python-Bibliothek spaCy.
Schritt 2: Automatisierte Annotationsgenerierung aus Bildern (computer vision-based)
2i. Laden Sie Galerie-Artefakte als Bilder mit der Europeana User Set API herunter.
2ii. Generierung beschreibender Bildunterschriften mithilfe von Computer Vision-Techniken mit vortrainierten KI-Modellen, insbesondere Varianten der Open-Source-Qwen-Modelle – Qwen3-VL-2B-Instruct multimodal visual-language model (VLM) und Qwen3.5-4B large language model (LLM).
2iii. Generieren Sie automatisierte Anmerkungen aus den Bildunterschriften.
Schritt 3: Erstellung von automatisierten Anmerkungen zur Crowdsourcing-Validierung (JSON-LD-Formatierung)
3i. Formatieren Sie alle generierten Anmerkungen basierend auf dem W3C-Anmerkungsmodell für die direkte Einnahme in der Crowdsourcing-Plattform CrowdHeritage.
3ii. Wandeln Sie die JSON-formatierten finalen Anmerkungen in ein maschinenlesbares CSV um und kombinieren Sie alle Anmerkungen aus den fünf Crowdsourcing-Workshops.
Schritt 4: Datenqualitätssicherung und Bias-Aware-Screening von vom Menschen validierten Anmerkungen
4i. Überprüfen Sie abschließende Anmerkungen gegen schädliche, voreingenommene oder strittige Begriffe im DE-BIAS-Wortschatz durch RDF-basierte Thesaurusabfrage.
Im Laufe von fünf Crowdsourcing-Workshops, die vor Ort und online stattfanden, überprüften 70 Teilnehmer, darunter Forscher, Studenten und Volkskunstexperten, KI-generierte Anmerkungen, bestätigten genaue Tags, lehnten irreführende durch Upvotes und Downvotes ab und trugen eigene zusätzliche Anmerkungen bei.
Dateneinblicke und ethische Bewertung
Die meisten Bilder wurden mit jeweils 15 bis 20 neuen beschreibenden Tags angereichert. Insgesamt wurden fast 55.000 Annotationsaktionen aufgezeichnet, darunter Tag-Generierung, Upvotes und Downvotes. Das Ergebnis ist die Öffnung reicherer Wege für die Entdeckung und Auseinandersetzung mit der ukrainischen Volkskunst. Die Metriken nach der Kampagne zeigen, dass die meisten KI-generierten Anmerkungen als genau akzeptiert wurden, wobei nur wenige abgelehnt wurden.
Diese fünf KI-generierten Tags erhielten die höchsten Akzeptanzraten:
- Ikone
- malen
- Mann
- Bäume
- Frau.
Diese fünf KI-generierten Tags erhielten die höchsten Ablehnungsraten:
- Risse
- tragen
- Schaden
- kleines Objekt
- Mitarbeiter.
Die Anwendung einer ethischen Folgenabschätzung auf die endgültigen Anmerkungen wurde als wichtiger Schritt im Pilotprojekt behandelt. Eine zweite Überprüfungsebene wurde durchgeführt, um potenziell problematische Sprache zu identifizieren und die Rechenschaftspflicht zu stärken. Durch das Screening der von Menschen zugelassenen Tags gegen das DE-BIAS-Wortschatz wurde ein Begriff identifiziert, Slave, der anschließend gemäß der Empfehlung auf versklavte Person überarbeitet wurde. Das Vokabular wurde vor der endgültigen Veröffentlichung des offenen Datensatzes als Maßnahme zur ethischen Folgenabschätzung angewandt, wobei die UNESCO-Empfehlung zur Ethik der künstlichen Intelligenz (2022) und das Instrument zur ethischen Folgenabschätzung (2023) berücksichtigt wurden.
Die Entwicklung des Pilotprojekts und das Verständnis seiner KI-bezogenen ethischen Dimensionen wurde auch durch die AISTER-Datenanalysestudie gestützt, in der 22 internationale Forschungsprojekte kartiert wurden, die künstliche Intelligenz und Bürgerbeteiligung für die Erhaltung des kulturellen Erbes in Notsituationen nutzen. In der Studie wurden die ausgewählten Projekte anhand des AISTER-Klassifizierungsrahmens klassifiziert, der eine systematische Kategorisierung in 24 analytische Dimensionen zur Analyse von KI-gesteuerten partizipativen Kulturerbeinitiativen bietet. Die Rahmendimensionen umfassen Bereiche des Kulturerbes, das Modell der Bürgerbeteiligung (Shirk et al., 2012) und das Kooperationsmodell (Carayannis & Campbell, 2009), neben KI-spezifischen Dimensionen, einschließlich KI-Technologietypen, das Modell der rationalen Agenten (Russell & Norvig, 2020, 4. Aufl.), die angewandte ethische KI-Typologie (Morley et al., 2019), Lizenztypen und mehr. Die Datenerkenntnisse der Studie werden als interaktive Open-Access-Webvisualisierungen veröffentlicht, die eine vergleichende Erkundung des Feldes ermöglichen. Der Pilotworkflow und die Ergebnisse werden in einem bevorstehenden Konferenzpapier veröffentlicht (Ziku, Zourou, & Kouzelis, 2026).
Schlussfolgerungen
Das Pilotprojekt zielte darauf ab, einen offenen und reproduzierbaren Weg für die Verwendung von KI-Tools zur großmaßstäblichen Verarbeitung von Daten in Kombination mit menschlicher Beteiligung, ethischer Bewertung und Datenerkenntnissen zu schaffen, um genauere, rechenschaftspflichtige, metrikgesteuerte und bereicherte Wege zur Entdeckung der ukrainischen Volkskunst zu unterstützen. Manchmal beginnt die zufällige Reise in das Erbe mit dem in ein Suchfeld eingegebenen Wort. Und manchmal können die richtigen Worte eine neue Kollektion ans Licht bringen.
Die drei aktivsten Mitwirkenden der Crowdsourcing-Kampagne erhielten ein Honorar sowie Gold-, Silber- und Bronzeabzeichen: Inna Kaika, Studentin in englischer Sprache und ausländischer Literatur, Mykola Gogol State University; Daria Markova, Studentin für Übersetzung, Staatliche Technische Universität Pryazovskyi; Marko Lakhmatov, Student in Cybersicherheit, Staatliche Technische Universität Pryazovskyi.
Inna äußerte sich zu ihrer Teilnahme wie folgt: „Die ukrainische Kunst spiegelt die Widerstandsfähigkeit und Kreativität unserer Menschen wider, und es ist wichtiger denn je, sie zu teilen. Angetrieben von dieser Leidenschaft habe ich mich der Kampagne angeschlossen, um das kulturelle Erbe zugänglicher zu machen. Besonders gefallen hat mir der Annotationsprozess und die Auseinandersetzung mit der ethnographischen Sammlung. Es war mir eine Ehre, einen Beitrag zu einem Projekt zu leisten, das Kunst und Technologie zusammenbringt.“
Erkundung und Wiederverwendung der Pilotressourcen
Sind Sie daran interessiert, ähnliche Methoden auf Ihre eigenen Sammlungen anzuwenden?
- Sehen Sie sich die Crowdsourcing-Kampagne für ukrainische Volkskunst auf CrowdHeritage an.
- Erkunden Sie das Human-in-the-Loop-Crowdsourcing-Pilotprojekt.
- Wiederverwendung der Open-Source-Jupyter-Notizbücher, die den gesamten Workflow vom Datenabruf über KI-generierte Anmerkungen bis hin zu plattformfähigen Exporten dokumentieren.
- Zugang zu den offenen Datensätzen im offenen Repository von Zenodo, die die Daten und Ergebnisse des Pilotprojekts zur Bewahrung, Zitierung und Wiederverwendung enthalten.
- Erkunden Sie die interaktiven Datenvisualisierungen und entdecken Sie Erkenntnisse aus 22 internationalen Forschungsinitiativen, die KI und Bürgerbeteiligung für die Erhaltung des kulturellen Erbes in Notsituationen und darüber hinaus nutzen.
Bestätigungen
Wir danken allen AISTER-Projektpartnern und -Mitarbeitern, insbesondere Yevgen Dmytruk vom Krovets Museum, Eirini Kaldeli von CrowdHeritage und Datoptron, Hugo Manguinhas von der Europeana Foundation und Uldis Zariņš und Sanita Reinsone von der Universität Lettland.
Ausgewählte Referenzen
- Die Dokumentation der Jupyter Notebooks folgt den Kriterien der Qualitätsbewertung für Jupyter-Projekte durch GLAM-Institutionen, die in Candela, G., Chambers, S., & Sherratt, T. (2023) veröffentlicht wurden. Ein Ansatz zur Bewertung der Qualität der von den GLAM-Institutionen veröffentlichten Jupyter-Projekte. Journal of the Association for Information Science and Technology, 74(13), 1550–1564.
- Die README-Dokumentation des Pilotprojekts auf GitHub übernimmt die Struktur der Git-basierten Datensatzdokumentation der KU Leuven Libraries. Siehe: KU Leuven Libraries, Abteilung Digitalisierung. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Version 01-beta2) [Datensatz]. Zenodo.
- M. Ziku, K. Zourou und A. Kouzelis, 'AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow“, 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Venedig, Italien, 7.-9. September 2026, in der Presse.