
Continue a ler para ter um vislumbre de um projeto-piloto reprodutível que combinou a utilização da plataforma Europeana.eu e das API, modelos de IA pré-treinados, modelização de códigos vivos e dados semânticos, contributos humanos numa plataforma de crowdsourcing, uma ferramenta de tesauro sensível a preconceitos e métricas de dados, o que levou ao enriquecimento de uma coleção etnográfica ucraniana na Europeana.eu através de 55 000 ações de anotação e quase 6 000 novas etiquetas de metadados.
Salvaguarda do património ucraniano liderada pelos cidadãos
Desde 2025, a Web2Learn – juntamente com as universidades do Luxemburgo, da Letónia, de Kiev Taras Shevchenko e da Fundação Europeana – colabora no AISTER, um projeto Erasmus+ que aborda a participação dos cidadãos com recurso à IA na salvaguarda do património cultural ucraniano. A Web2Learn contribui com a sua experiência em inovação orientada para os cidadãos para o projeto utilizando tecnologias de fonte aberta que promovem a educação, a formação e a cidadania ativa.

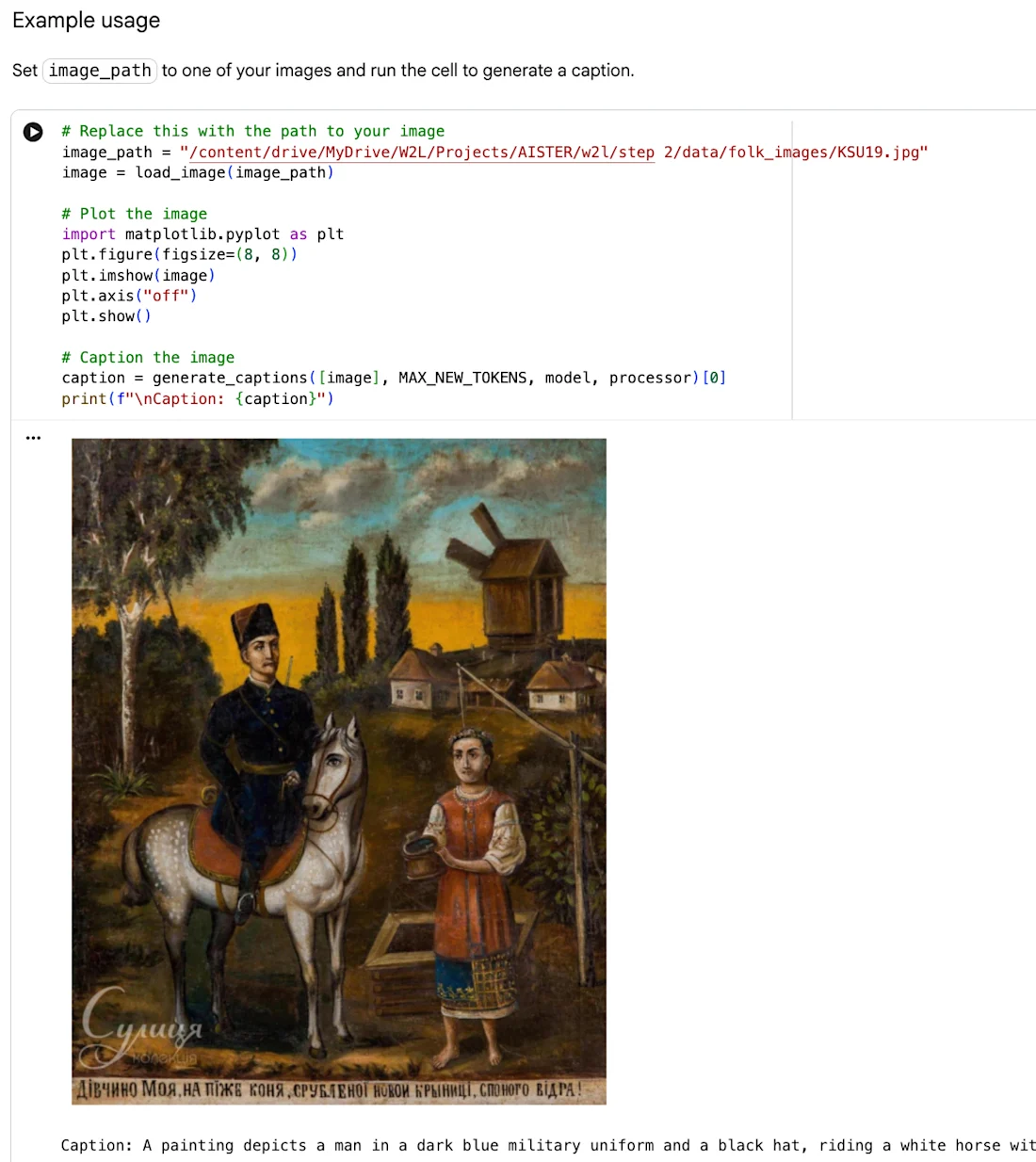
HITL Crowdsourcing Pilot Poster by Web2Learn incorpora Folk Painting "Retrato de uma menina", como atribuído acima, incorporado na presente composição com permissão adicional do detentor dos direitos.
O consórcio AISTER previu uma série de workshops com a participação de investigadores, estudantes e jovens profissionais para a duração do projeto. Cinco seminários liderados pela Web2Learn em linha e presenciais na Biblioteca da Universidade da Letónia proporcionaram a oportunidade de realizar um projeto-piloto: testar um fluxo de trabalho humano em circuito para enriquecer as coleções digitais de imagens através do crowdsourcing e de ferramentas de IA, convidando os participantes no seminário a dialogarem com o património etnográfico ucraniano e a tornarem-se contribuintes ativos, enriquecendo e validando as etiquetas de descrição geradas pela IA.
O projeto-piloto foi concebido como um recurso aberto e reprodutível, com documentação pormenorizada para facilitar a investigação e a formação em ciências humanas digitais, e é disponibilizado gratuitamente para reutilização por académicos, estudantes e professores, bem como para reutilização criativa.
Arte popular ucraniana na Europeana.eu
Em 2025, o Museu de Arte Tradicional da Ucrânia em linha Krovets, que funciona desde 2014 graças aos esforços voluntários dos fundadores do museu, publicou um conjunto de dados sobre a Europeana.eu através do agregador MUSEU, que inclui 3 840 artefactos do património etnográfico, incluindo trajes tradicionais, artesanato têxtil, arte popular, cultura material e fotografias.
As imagens utilizadas para o piloto originam-se desta coleção etnográfica. No âmbito do projeto-piloto, foi publicada uma galeria de arte folclórica ucraniana na Europeana.eu, que dá acesso à subcoleção de arte folclórica do museu, que inclui 312 artefactos classificados como pinturas folclóricas ou ícones folclóricos. A maioria das pinturas, que retratam a vida rural cotidiana, folclore e temas religiosos, originam-se das regiões etnográficas centrais da Ucrânia, Podniprovia Média e Poltavshchyna, e datam principalmente do início e meados do século XX.
A coleção é composta principalmente de cenas de gênero, paisagens e retratos individuais. As pinturas folclóricas formam narrativas visuais, oferecendo instantâneos de paisagens rurais, tradições religiosas, motivos de arte folclórica e cultura material cotidiana. Muitos dos detalhes são fáceis de perceber ao olhar para as imagens, mas nem sempre são fáceis de descobrir através da pesquisa.
O piloto de crowdsourcing humano-no-loop
O projeto-piloto visava criar um novo nível de visibilidade para a arte popular ucraniana. Desenvolveu um fluxo de trabalho que combina a utilização de API da Europeana, métodos baseados na IA para o processamento de linguagem natural e a visão por computador, o Jupyter Notebook como um espaço de trabalho interativo para codificação reprodutível e o tratamento de dados baseado na ética, juntamente com a participação do público através da plataforma de crowdsourcing CrowdHeritage para criar etiquetas de descrição em geral pesquisáveis, validadas pelo ser humano e avaliadas eticamente.
Para começar, foram utilizadas duas API da Europeana para obter os itens da galeria e os metadados, a API do conjunto de utilizadores da Europeana para aceder às galerias geradas pelos utilizadores publicada na Europeana e a API de pesquisa da Europeana para a recuperação de metadados do conteúdo acedido na Europeana, modelizada utilizando o modelo de dados da Europeana (EDM). Em seguida, foram geradas novas anotações descritivas com ferramentas de IA que empregaram modelos de IA pré-treinados de código aberto e bibliotecas em processamento de linguagem natural e visão computacional. As anotações automatizadas foram geradas em Cadernos Jupyter e serializadas em JSON-LD de acordo com o Modelo de Dados de Anotações Web do W3C (World Wide Web Consortium), para apoiar a sua importação para a plataforma de crowdsourcing CrowdHeritage mantida pela Datoptron.
No total, o piloto desenvolveu oito Cadernos Jupyter, que funcionaram como ambientes de computação interativos que permitem a codificação ao vivo e a reprodutibilidade para apoiar a execução de ponta a ponta das etapas de processamento de dados. Os computadores portáteis foram implementados no Google Colab para permitir a colaboração e a coedição em tempo real e depois transferidos como um repositório aberto no GitHub para controlo de versões, facilitando a transparência e a rastreabilidade da otimização colaborativa de códigos. Abrangem todo o processo de dados do projeto-piloto em etapas sequenciais, que incluem:
Etapa 1: Geração automática de anotação a partir de metadados textuais (baseados no PNL)
1i. Recuperar os identificadores dos artigos na Galeria de Arte Popular Ucraniana publicada utilizando o conjunto de utilizadores ΑPI da Europeana e obter metadados textuais (por exemplo, títulos, temas) dos artefactos utilizando a API de pesquisa da Europeana.
1ii. Gerar anotações automatizadas (etiquetas de descrição) a partir dos metadados usando técnicas de processamento de linguagem natural (NLP), particularmente heurísticas baseadas em regras e Reconhecimento de Entidade Nomeada (NER) usando a biblioteca de código aberto Python spaCy.
Etapa 2: Geração automática de anotação a partir de imagens (computer vision-based)
2i. Descarregar artefactos da Galeria como imagens utilizando a API Europeana User Set.
2ii. Gerar legendas descritivas de imagens utilizando técnicas de visão computacional com modelos de IA pré-treinados, em especial variantes dos modelos Qwen de código aberto – modelo multimodal de linguagem visual Qwen3-VL-2B-Instruct (VLM) e modelo de linguagem grande Qwen3.5-4B (LLM).
2iii. Gere anotações automáticas a partir das legendas da imagem.
Etapa 3: Preparação de anotações automatizadas para validação crowdsourced (formatação JSON-LD)
3i. Formatar todas as anotações geradas com base no modelo de anotações W3C para ingestão direta na plataforma de crowdsourcing CrowdHeritage.
3ii. Converta as anotações finais formatadas em JSON num CSV legível por máquina e combine todas as anotações das cinco oficinas de crowdsourcing.
Passo 4: Garantia da qualidade dos dados e análise das anotações validadas por seres humanos com conhecimento de causa
4i. Verifique as anotações finais contra termos prejudiciais, tendenciosos ou contenciosos no Vocabulário DE-BIAS através da consulta do tesauro baseado em RDF.
Ao longo de cinco seminários de crowdsourcing realizados no local e em linha, 70 participantes, incluindo investigadores, estudantes universitários e especialistas em arte popular, analisaram as anotações geradas pela IA, confirmando etiquetas precisas, rejeitando as enganosas através de votos positivos e negativos e contribuindo com anotações adicionais próprias.
Informações sobre os dados e avaliação ética
A maioria das imagens foi enriquecida com 15 a 20 novas etiquetas descritivas cada. No total, foram registadas quase 55 000 ações de anotação, incluindo geração de tags, votos positivos e votos negativos. O resultado é abrir vias mais ricas para descobrir e interagir com a arte popular ucraniana. As métricas pós-campanha revelam que a maioria das anotações geradas pela IA foram aceites como exatas, sendo apenas algumas rejeitadas.
Estas cinco etiquetas geradas por IA receberam as taxas de aceitação mais elevadas:
- ícone
- pintura
- homem
- árvores
- mulher.
Estas cinco etiquetas geradas por IA receberam as taxas de rejeição mais elevadas:
- fissuras
- desgaste
- danos
- pequeno objeto
- pessoal.
A aplicação de uma avaliação de impacto ético às anotações finais foi tratada como um passo importante no projeto-piloto. Foi realizado um segundo nível de análise para identificar linguagem potencialmente problemática e reforçar a responsabilização. A triagem das etiquetas aprovadas por humanos contra o Vocabulário DE-BIAS identificou um termo, escravo, que foi posteriormente revisto para escravizado de acordo com a recomendação. O vocabulário foi aplicado como uma medida de avaliação de impacto ético antes da publicação final do conjunto de dados abertos, tendo em conta a Recomendação da UNESCO sobre a ética da inteligência artificial (2022) e o instrumento de avaliação de impacto ético (2023).
O desenvolvimento do projeto-piloto e a compreensão das suas dimensões éticas relacionadas com a IA foram igualmente tidos em conta no estudo de análise de dados AISTER, que mapeou 22 projetos de investigação internacionais que utilizam a inteligência artificial e a participação dos cidadãos para a preservação do património cultural em contextos de emergência. O estudo classificou os projetos selecionados utilizando o quadro de classificação AISTER, que oferece uma categorização sistemática em 24 dimensões analíticas concebidas para analisar iniciativas de património participativo baseadas na IA. As dimensões do quadro incluem domínios do património cultural, o modelo de participação dos cidadãos (Shirk et al., 2012) e o modelo de cooperação (Carayannis & Campbell, 2009), juntamente com dimensões específicas da IA, incluindo tipos de tecnologia de IA, o modelo de agente racional (Russell & Norvig, 2020, 4.a edição), a tipologia de IA ética aplicada (Morley et al., 2019), tipos de licenças e muito mais. Os dados do estudo são publicados sob a forma de visualizações Web interativas de acesso aberto que oferecem uma exploração comparativa do domínio. O fluxo de trabalho e as conclusões do projeto-piloto são publicados num próximo documento de conferência (Ziku, Zourou, & Kouzelis, 2026).
Conclusões
O projeto-piloto visou criar uma via aberta e reprodutível para a utilização de ferramentas de IA para o tratamento de dados em grande escala, combinada com a participação humana, a avaliação ética e as informações sobre os dados, a fim de apoiar formas mais precisas, responsáveis, baseadas em métricas e enriquecidas de descobrir a arte popular ucraniana. Por vezes, a viagem acidental para o património começa com a palavra digitada numa caixa de pesquisa. E, às vezes, as palavras certas podem trazer uma nova coleção à luz.
Os três contribuintes mais ativos para a campanha de crowdsourcing receberam um honorário, bem como emblemas de ouro, prata e bronze, respectivamente: Inna Kaika, estudante de Língua Inglesa e Literatura Estrangeira, Universidade Estatal de Mykola Gogol; Daria Markova, estudante de Tradução, Universidade Técnica Estatal de Pryazovskyi; Marko Lakhmatov, estudante de cibersegurança, Universidade Técnica Estatal de Pryazovskyi.
Refletindo sobre a sua participação, Inna partilhou: «A arte ucraniana reflete a resiliência e a criatividade do nosso povo, e partilhá-la é mais importante do que nunca. Impulsionado por esta paixão, juntei-me à campanha para tornar o património cultural mais acessível. Gostei especialmente do processo de anotação e da exploração da coleção etnográfica. Foi uma honra contribuir para um projeto que reúne arte e tecnologia.»
Explorar e reutilizar os recursos-piloto
Interessado em aplicar métodos semelhantes às suas próprias coleções?
- Veja a campanha de crowdsourcing para a arte popular ucraniana no CrowdHeritage.
- Explorar o projeto-piloto de crowdsourcing «human-in-the-loop».
- Reutilizar os computadores portáteis Jupyter de fonte aberta , que documentam todo o fluxo de trabalho, desde a recuperação de dados até às anotações geradas pela IA e às exportações preparadas para plataformas.
- Aceda aos conjuntos de dados abertos no repositório aberto do Zenodo, que incluem os dados e resultados do projeto-piloto para preservação, citação e reutilização.
- Explore as visualizações interativas de dados e descubra informações de 22 iniciativas internacionais de investigação que utilizam a IA e a participação dos cidadãos para a preservação do património cultural em contextos de emergência e não só.
Agradecimentos
Gostaríamos de agradecer a todos os parceiros e colaboradores do projeto AISTER, e particularmente a Yevgen Dmytruk no Museu Krovets, Eirini Kaldeli no CrowdHeritage e Datoptron, Hugo Manguinhas na Fundação Europeana e Uldis Zariņš e Sanita Reinsone na Universidade da Letónia.
Referências selecionadas
- A documentação dos Cadernos Jupyter segue os critérios de avaliação da qualidade dos projetos Jupyter pelas instituições GLAM, publicados em Candela, G., Chambers, S., & Sherratt, T. (2023). Uma abordagem para avaliar a qualidade dos projetos Jupyter publicados pelas instituições GLAM. Journal of the Association for Information Science and Technology (Jornal da Associação das Ciências e Tecnologias da Informação), 74(13), 1550-1564.
- A documentação README do projeto-piloto sobre o GitHub adota a estrutura da documentação do conjunto de dados da KU Leuven Libraries baseada no Git. Ver: KU Leuven Libraries, Departamento de Digitalização. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Versão 01-beta2) [Conjunto de dados]. Zenodo.
- M. Ziku, K. Zourou e A. Kouzelis, «AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow, Conferência Internacional IEEE 2026 sobre Ciberhumanidades (IEEE-CH), Veneza, Itália, 7-9 de setembro de 2026, na imprensa.