
Zapraszamy do zapoznania się z powtarzalnym projektem pilotażowym, który połączył korzystanie z platformy Europeana.eu i interfejsów API, wstępnie wyszkolonych modeli sztucznej inteligencji, kodowania na żywo i semantycznego modelowania danych, współpracowników na platformie crowdsourcingowej, narzędzia tezaurusa ze świadomością stronniczości i wskaźników danych, co doprowadziło do wzbogacenia ukraińskiego zbioru etnograficznego na stronie Europeana.eu o 55 000 adnotacji i prawie 6 000 nowych metadanych.
Prowadzona przez obywateli ochrona ukraińskiego dziedzictwa
Od 2025 r. Web2Learn – wraz z uniwersytetami w Luksemburgu, na Łotwie, w Kijowie Tarasem Szewczenką i Fundacją Europeana – współpracuje nad projektem AISTER, który dotyczy uczestnictwa obywateli opartego na sztucznej inteligencji w ochronie ukraińskiego dziedzictwa kulturowego. Web2Learn wnosi swoją wiedzę fachową w zakresie innowacji inspirowanych przez obywateli do projektu z wykorzystaniem technologii open source, które wspierają edukację, szkolenia i aktywne obywatelstwo.

HITL Crowdsourcing Pilot Poster by Web2Learn zawiera Folk Malarstwo "Portret dziewczyny", jak przypisano powyżej, włączone do obecnej kompozycji za dodatkową zgodą posiadacza praw.
Konsorcjum AISTER przewidziało serię warsztatów z udziałem naukowców, studentów i młodych specjalistów na czas trwania projektu. Pięć warsztatów prowadzonych przez Web2Learn online i na miejscu w Bibliotece Uniwersytetu Łotewskiego było okazją do przeprowadzenia projektu pilotażowego: przetestowanie przepływu pracy w obiegu ludzkim w celu wzbogacenia cyfrowych kolekcji obrazów za pomocą crowdsourcingu i narzędzi sztucznej inteligencji, zachęcając uczestników warsztatów do zaangażowania się w ukraińskie dziedzictwo etnograficzne i stania się aktywnymi współpracownikami poprzez wzbogacenie i walidację znaczników opisu wygenerowanych przez sztuczną inteligencję.
Pilotaż został zaprojektowany jako otwarty i odtwarzalny zasób ze szczegółową dokumentacją w celu ułatwienia badań i szkoleń w dziedzinie humanistyki cyfrowej i jest bezpłatnie udostępniany do ponownego wykorzystania przez naukowców, studentów i nauczycieli, a także do kreatywnego ponownego wykorzystania.
Ukraińska sztuka ludowa na Europeana.eu
W 2025 r. działające od 2014 r. dzięki dobrowolnym wysiłkom założycieli muzeum internetowe muzeum sztuki tradycyjnej Krovets Online Museum of Traditional Art of Ukraine opublikowało za pośrednictwem agregatora MUSEU zbiór danych na temat Europeana.eu, który obejmuje 3840 artefaktów dziedzictwa etnograficznego, w tym tradycyjne stroje, rzemiosło włókiennicze, sztukę ludową, kulturę materialną i fotografie.
Obrazy użyte do pilotażu pochodzą z tej kolekcji etnograficznej. W ramach projektu pilotażowego na stronie Europeana.eu opublikowano Galerię ukraińskiej sztuki ludowej, która zapewnia dostęp do podzbioru sztuki ludowej muzeum, obejmującego 312 artefaktów sklasyfikowanych jako obrazy ludowe lub ikony ludowe. Większość obrazów, przedstawiających codzienne życie wiejskie, folklor i tematy religijne, pochodzi z centralnych etnograficznych regionów Ukrainy, Środkowego Podnieprowa i Połtawszczyzny i pochodzi głównie z początku i połowy XX wieku.
Kolekcja składa się przede wszystkim ze scen gatunkowych, pejzaży i indywidualnych portretów. Obrazy ludowe tworzą narracje wizualne, oferując migawki wiejskich krajobrazów, tradycji religijnych, motywów sztuki ludowej i codziennej kultury materialnej. Wiele szczegółów można łatwo zauważyć, patrząc na zdjęcia, ale nie zawsze łatwo je odkryć poprzez wyszukiwanie.
Pilot crowdsourcingu typu człowiek w pętli
Celem projektu pilotażowego było stworzenie nowej warstwy widoczności ukraińskiej sztuki ludowej. Opracował on przepływ pracy, który łączy wykorzystanie interfejsów API Europeany, opartych na sztucznej inteligencji metod przetwarzania języka naturalnego i widzenia komputerowego, Jupyter Notebook jako interaktywnej przestrzeni roboczej do odtwarzalnego kodowania i przetwarzania danych opartego na etyce, wraz z zaangażowaniem publicznym za pośrednictwem platformy crowdsourcingowej CrowdHeritage w celu stworzenia wyszukiwalnych, zatwierdzonych przez człowieka i etycznie ocenianych tagów opisowych.
Aby rozpocząć, wykorzystano dwa interfejsy API Europeany do pobierania elementów galerii i metadanych, interfejs API zestawu użytkowników Europeany do uzyskiwania dostępu do galerii generowanych przez użytkowników opublikowanych na stronie Europeany oraz interfejs API wyszukiwania Europeany do wyszukiwania metadanych w celu wyszukiwania treści, do których uzyskano dostęp na stronie Europeany, wzorowany na modelu danych Europeany (EDM). Następnie wygenerowano nowe opisowe adnotacje za pomocą narzędzi sztucznej inteligencji, które wykorzystywały wstępnie wyszkolone modele i biblioteki sztucznej inteligencji o otwartym kodzie źródłowym w przetwarzaniu języka naturalnego i widzeniu komputerowym. Zautomatyzowane adnotacje zostały wygenerowane w notebookach Jupyter i serializowane w JSON-LD zgodnie z modelem danych adnotacji internetowych W3C (World Wide Web Consortium), aby wspierać ich import do platformy crowdsourcingowej CrowdHeritage utrzymywanej przez Datoptron.
W sumie pilot opracował osiem notebooków Jupyter, które funkcjonowały jako interaktywne środowiska obliczeniowe, które umożliwiają kodowanie na żywo i odtwarzalność w celu wsparcia pełnego wykonania etapów przetwarzania danych. Notatniki zostały wdrożone w Google Colab, aby umożliwić współpracę i współredagowanie w czasie rzeczywistym, a następnie przeniesione jako otwarte repozytorium na GitHub w celu kontroli wersji, ułatwiając przejrzystość i identyfikowalność wspólnej optymalizacji kodu. Obejmują one pełny proces danych pilota w kolejnych etapach, które obejmują:
Krok 1: Zautomatyzowane generowanie adnotacji z metadanych tekstowych (na podstawie NLP)
1i. Pobierz identyfikatory przedmiotów w opublikowanej Galerii ukraińskiej sztuki ludowej za pomocą zestawu użytkowników Europeana ΑPI i pobierz metadane tekstowe (np. tytuły, tematy) artefaktów za pomocą interfejsu API wyszukiwania Europeana.
1ii. Generowanie automatycznych adnotacji (znaczników opisowych) z metadanych przy użyciu technik przetwarzania języka naturalnego (NLP), w szczególności heurystyki opartej na regułach i rozpoznawania nazw podmiotów (NER) przy użyciu biblioteki Python spaCy o otwartym kodzie źródłowym.
Etap 2: Automatyczne generowanie adnotacji z obrazów (oparte na wizji komputerowej)
2i. Pobierz artefakty galerii jako obrazy za pomocą interfejsu API zestawu użytkowników Europeana.
2ii. Generowanie opisowych napisów do obrazów za pomocą komputerowych technik wizyjnych za pomocą wstępnie wyszkolonych modeli sztucznej inteligencji, w szczególności wariantów modeli Qwen typu open source – multimodalnego wizualnego modelu językowego Qwen3-VL-2B-Instruct (VLM) i wielkojęzycznego modelu językowego Qwen3.5-4B (LLM).
2iii. Generowanie automatycznych adnotacji z podpisów obrazów.
Etap 3: Przygotowanie automatycznych adnotacji do walidacji crowdsourcingowej (formatowanie JSON-LD)
3i. Sformatuj wszystkie wygenerowane adnotacje w oparciu o model adnotacji W3C do bezpośredniego spożycia na platformie crowdsourcingowej CrowdHeritage.
3ii. Konwertuj końcowe adnotacje w formacie JSON na CSV do odczytu maszynowego i połącz wszystkie adnotacje z pięciu warsztatów crowdsourcingowych.
Etap 4: Zapewnienie jakości danych i kontrola adnotacji zatwierdzonych przez człowieka pod kątem stronniczości
4i. Sprawdź końcowe adnotacje pod kątem szkodliwych, stronniczych lub kontrowersyjnych terminów w słowniku DE-BIAS za pomocą zapytania tezaurusa opartego na RDF.
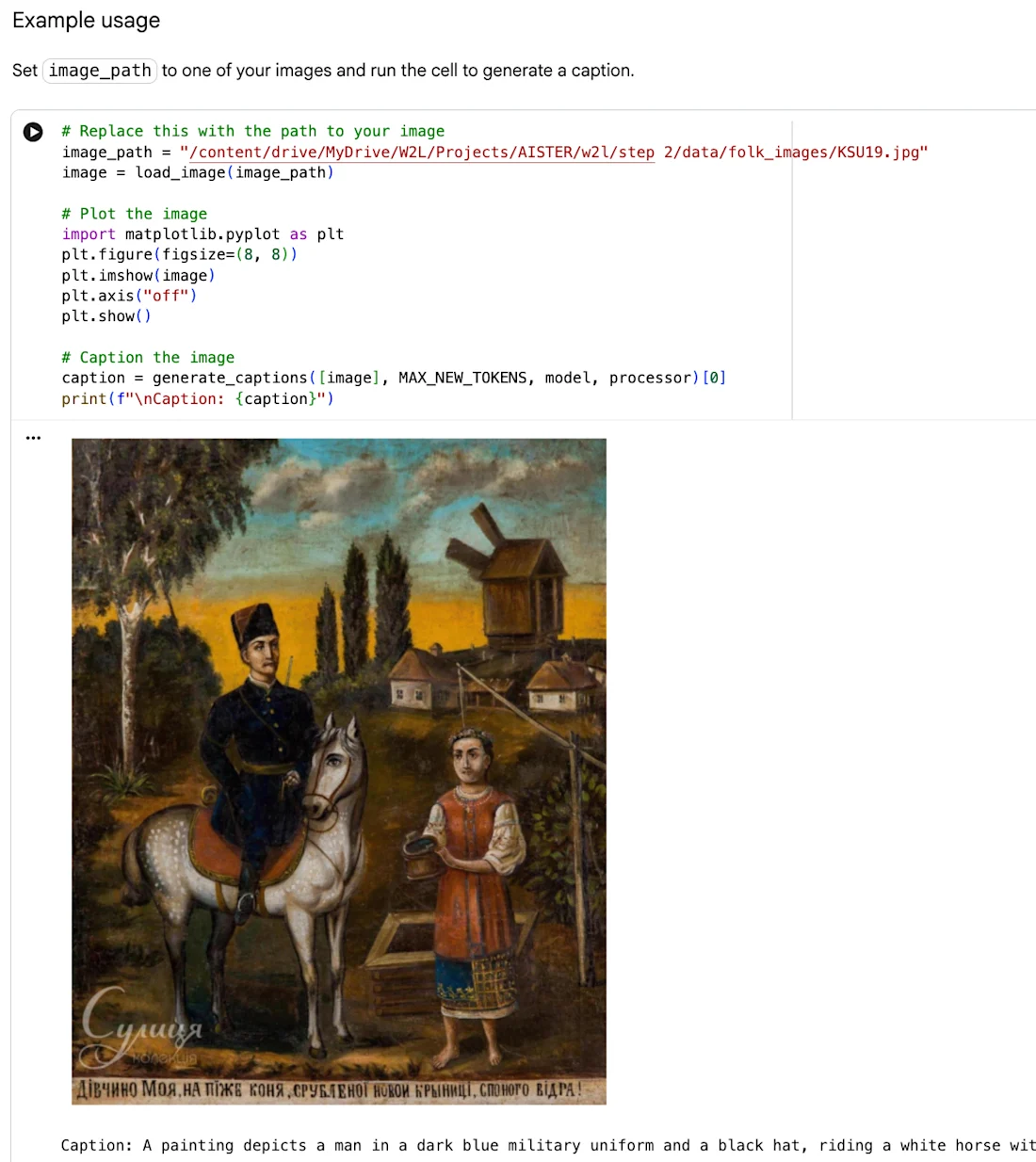
Podczas pięciu warsztatów crowdsourcingowych, które odbyły się na miejscu i online, 70 uczestników, w tym badacze, studenci i eksperci sztuki ludowej, przeanalizowało adnotacje generowane przez sztuczną inteligencję, potwierdzając dokładne tagi, odrzucając wprowadzające w błąd poprzez głosy upvotes i downvotes oraz dodając własne dodatkowe adnotacje.
Wgląd w dane i ocena etyczna
Większość zdjęć została wzbogacona o 15 do 20 nowych tagów opisowych. Ogółem zarejestrowano prawie 55 000 działań adnotacyjnych, w tym generowanie tagów, głosy upvotes i downvotes. Rezultatem jest otwarcie bogatszych ścieżek odkrywania ukraińskiej sztuki ludowej i angażowania się w nią. Wskaźniki po kampanii pokazują, że większość adnotacji generowanych przez sztuczną inteligencję została zaakceptowana jako dokładna, a tylko kilka z nich zostało odrzuconych.
Te pięć tagów wygenerowanych przez sztuczną inteligencję otrzymało najwyższe wskaźniki akceptacji:
- ikona
- malowanie
- człowiek
- drzewa
- kobieta.
Te pięć tagów wygenerowanych przez sztuczną inteligencję otrzymało najwyższe wskaźniki odrzuceń:
- pęknięcia
- załóż
- uszkodzenia
- drobny przedmiot
- personel.
Zastosowanie oceny wpływu etycznego do końcowych adnotacji potraktowano jako ważny krok w projekcie pilotażowym. Przeprowadzono drugą warstwę przeglądu w celu zidentyfikowania potencjalnie problematycznego języka i wzmocnienia rozliczalności. Przeglądając zatwierdzone przez człowieka znaczniki ze słownikiem DE-BIAS zidentyfikowano jeden termin, niewolnik, który następnie został zmieniony na osobę zniewoloną zgodnie z zaleceniem. Słownictwo to stosowano jako środek oceny skutków etycznych przed ostateczną publikacją otwartego zbioru danych, z uwzględnieniem zalecenia UNESCO w sprawie etyki sztucznej inteligencji (2022 r.) i narzędzia oceny skutków etycznych (2023 r.).
Opracowanie projektu pilotażowego i zrozumienie jego wymiaru etycznego związanego ze sztuczną inteligencją opierało się również na analizie danych AISTER, w której przedstawiono 22 międzynarodowe projekty badawcze wykorzystujące sztuczną inteligencję i udział obywateli do ochrony dziedzictwa kulturowego w sytuacjach nadzwyczajnych. W badaniu sklasyfikowano wybrane projekty przy użyciu ram klasyfikacji AISTER, które oferują systematyczną kategoryzację w 24 wymiarach analitycznych przeznaczonych do analizy inicjatyw w zakresie dziedzictwa partycypacyjnego opartych na sztucznej inteligencji. Wymiary ramowe obejmują dziedziny dziedzictwa kulturowego, model uczestnictwa obywateli (Shirk i in., 2012 r.) oraz model współpracy (Carayannis & Campbell, 2009 r.), a także wymiary specyficzne dla sztucznej inteligencji, w tym rodzaje technologii sztucznej inteligencji, model racjonalnego agenta (Russell & Norvig, 2020 r., wydanie czwarte), zastosowaną etyczną typologię sztucznej inteligencji (Morley i in., 2019 r.), rodzaje licencji i inne. Spostrzeżenia dotyczące danych zawarte w badaniu są publikowane jako interaktywne wizualizacje internetowe o otwartym dostępie, które oferują porównawczą eksplorację tej dziedziny. Pilotażowy obieg prac i ustalenia zostaną opublikowane w nadchodzącym dokumencie konferencyjnym (Ziku, Zourou, & Kouzelis, 2026).
Wnioski
Celem projektu pilotażowego było stworzenie otwartej i powtarzalnej ścieżki wykorzystania narzędzi sztucznej inteligencji do przetwarzania danych na dużą skalę, w połączeniu z uczestnictwem człowieka, oceną etyczną i wglądem w dane, w celu wspierania dokładniejszych, bardziej odpowiedzialnych, opartych na wskaźnikach i wzbogaconych sposobów odkrywania ukraińskiej sztuki ludowej. Czasami nieoczekiwana podróż do dziedzictwa zaczyna się od słowa wpisanego w pole wyszukiwania. A czasami właściwe słowa mogą wydobyć na światło dzienne nową kolekcję.
Trzej najbardziej aktywni uczestnicy kampanii crowdsourcingowej otrzymali odpowiednio honorarium oraz odznaki złote, srebrne i brązowe: Inna Kaika, studentka języka angielskiego i literatury obcej, Mykola Gogol State University; Daria Markova, studentka tłumaczeń pisemnych, Pryazovskyi State Technical University; Marko Lakhmatov, student cyberbezpieczeństwa, Pryazovskyi State Technical University.
Zastanawiając się nad swoim udziałem, Inna powiedziała: „Sztuka ukraińska odzwierciedla odporność i kreatywność naszych ludzi, a dzielenie się nią jest ważniejsze niż kiedykolwiek. Kierując się tą pasją, przyłączyłem się do kampanii na rzecz zwiększenia dostępności dziedzictwa kulturowego. Szczególnie podobał mi się proces adnotacji i eksploracja kolekcji etnograficznej. To był zaszczyt uczestniczyć w projekcie łączącym sztukę i technologię”.
Przeglądanie i ponowne wykorzystywanie zasobów pilotażowych
Interesuje Cię stosowanie podobnych metod do własnych kolekcji?
- Zobacz kampanię crowdsourcingową dla ukraińskiej sztuki ludowej na CrowdHeritage.
- Poznaj pilotaż crowdsourcingu „human-in-the-loop”.
- Ponownie wykorzystaj otwarte notesy Jupyter, które dokumentują pełny przepływ pracy od pobierania danych do adnotacji generowanych przez sztuczną inteligencję i eksportu gotowego na platformę.
- Dostęp do otwartych zbiorów danych w otwartym repozytorium Zenodo, które obejmują dane i wyniki projektu pilotażowego w celu zachowania, cytowania i ponownego wykorzystania.
- Zapoznaj się z interaktywnymi wizualizacjami danych i poznaj spostrzeżenia z 22 międzynarodowych inicjatyw badawczych, które wykorzystują sztuczną inteligencję i uczestnictwo obywateli do ochrony dziedzictwa kulturowego w sytuacjach nadzwyczajnych i poza nimi.
Podziękowania
Dziękujemy wszystkim partnerom i współpracownikom projektu AISTER, w szczególności Yevgenowi Dmytrukowi w Muzeum Krovets, Eirini Kaldeli w CrowdHeritage i Datoptron, Hugo Manguinhasowi w Fundacji Europeana oraz Uldisowi Zariņšowi i Sanicie Reinsone na Uniwersytecie Łotewskim.
Wybrane referencje
- Dokumentacja Jupyter Notebooks jest zgodna z kryteriami oceny jakości projektów Jupyter przez instytucje GLAM, opublikowanymi w Candela, G., Chambers, S., & Sherratt, T. (2023). Podejście do oceny jakości projektów Jupyter publikowanych przez instytucje GLAM. Journal of the Association for Information Science and Technology, 74(13), 1550–1564.
- Dokumentacja README projektu pilotażowego dotycząca GitHub przyjmuje strukturę dokumentacji zbioru danych KU Leuven Libraries Git. Zob.: KU Leuven Libraries, Dział Cyfryzacji. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (wersja 01-beta2) [zestaw danych]. Zenodo, właśc.
- M. Ziku, K. Zourou i A. Kouzelis, „AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow, IEEE International Conference on Cyber Humanities (IEEE-CH) 2026, Wenecja, Włochy, 7–9 września 2026 r., w prasie.