
Siga leyendo para echar un vistazo a un piloto reproducible que combinó el uso de la plataforma y las API de Europeana.eu, modelos de IA preentrenados, código en vivo y modelado de datos semánticos, contribuyentes humanos en una plataforma de crowdsourcing, una herramienta de tesauros y métricas de datos conscientes de los sesgos, lo que llevó al enriquecimiento de una colección etnográfica ucraniana en Europeana.eu a través de 55.000 acciones de anotación y casi 6.000 nuevas etiquetas de metadatos.
Salvaguardia del patrimonio ucraniano dirigida por los ciudadanos
Desde 2025, Web2Learn, junto con las universidades de Luxemburgo, Letonia, Kiev Taras Shevchenko y la Fundación Europeana, ha colaborado en AISTER, un proyecto Erasmus+ que aborda la participación ciudadana habilitada por la IA en la salvaguardia del patrimonio cultural ucraniano. Web2Learn aporta su experiencia en innovación impulsada por los ciudadanos al proyecto utilizando tecnologías de código abierto que fomentan la educación, la formación y la ciudadanía activa.

HITL Crowdsourcing Pilot Poster by Web2Learn incorpora Folk Painting "Portrait of a girl" como se atribuyó anteriormente, incorporado a la presente composición con permiso adicional del titular de los derechos.
El consorcio AISTER ha previsto una serie de talleres con la participación de investigadores, estudiantes y jóvenes profesionales durante la duración del proyecto. Cinco talleres dirigidos por Web2Learn en línea e in situ en la Biblioteca de la Universidad de Letonia brindaron la oportunidad de llevar a cabo un proyecto piloto: probar un flujo de trabajo humano en el bucle para enriquecer las colecciones digitales de imágenes a través de crowdsourcing y herramientas de IA, invitando a los participantes del taller a comprometerse con el patrimonio etnográfico ucraniano y convertirse en contribuyentes activos mediante el enriquecimiento y la validación de etiquetas de descripción generadas por IA.
El piloto fue diseñado como un recurso abierto y reproducible con documentación detallada para facilitar la investigación y capacitación en humanidades digitales, y está disponible gratuitamente para su reutilización por parte de académicos, estudiantes y maestros, así como para su reutilización creativa.
Arte popular ucraniano en Europeana.eu
En 2025, el Museo en línea de arte tradicional de Ucrania de Krovets, que funciona desde 2014 gracias a los esfuerzos voluntarios de los fundadores del museo, publicó un conjunto de datos en Europeana.eu a través del agregador MUSEU, que comprende 3 840 artefactos del patrimonio etnográfico, incluidos trajes tradicionales, artesanía textil, arte popular, cultura material y fotografías.
Las imágenes utilizadas para el piloto provienen de esta colección etnográfica. Como parte del proyecto piloto, se publicó en Europeana.eu una galería de arte popular ucraniano, que ofrece acceso a la subcolección de arte popular del museo, que incluye 312 artefactos clasificados como pinturas populares o iconos populares. La mayoría de las pinturas, que representan la vida rural cotidiana, el folclore y los temas religiosos, se originan en las regiones etnográficas centrales de Ucrania, Podniprovia media y Poltavshchyna, y datan principalmente de principios y mediados del siglo XX.
La colección se compone principalmente de escenas de género, paisajes y retratos individuales. Las pinturas populares forman narrativas visuales, ofreciendo instantáneas de paisajes rurales, tradiciones religiosas, motivos de arte popular y cultura material cotidiana. Muchos de los detalles son fáciles de notar al mirar las imágenes, pero no siempre son fáciles de descubrir a través de la búsqueda.
El piloto de crowdsourcing humano en el bucle
El proyecto piloto tenía por objeto crear una nueva capa de visibilidad para el arte popular ucraniano. Desarrolló un flujo de trabajo que combina el uso de las API de Europeana, métodos basados en la IA para el procesamiento del lenguaje natural y la visión por ordenador, Jupyter Notebook como espacio de trabajo interactivo para la codificación reproducible y el procesamiento de datos basado en la ética, junto con la participación pública a través de la plataforma de crowdsourcing CrowdHeritage para crear etiquetas de descripción consultables, validadas por humanos y evaluadas éticamente en general.
Para empezar, se utilizaron dos API de Europeana para obtener los elementos y metadatos de la galería, la API del conjunto de usuarios de Europeana para acceder a galerías generadas por los usuarios publicada en Europeana y la API de búsqueda de Europeana para la recuperación de metadatos de contenido accedido en Europeana, modelada utilizando el Modelo de Datos de Europeana (EDM). Luego, se generaron nuevas anotaciones descriptivas con herramientas de IA que empleaban modelos de IA preentrenados de código abierto y bibliotecas en el procesamiento del lenguaje natural y la visión por computadora. Las anotaciones automatizadas se generaron en Jupyter Notebooks y se serializaron en JSON-LD de acuerdo con el modelo de datos de anotación web del W3C (World Wide Web Consortium), para apoyar su importación en la plataforma de crowdsourcing CrowdHeritage mantenida por Datoptron.
En total, el piloto desarrolló ocho Jupyter Notebooks, que funcionaron como entornos informáticos interactivos que permiten la codificación en vivo y la reproducibilidad para apoyar la ejecución de extremo a extremo de los pasos de procesamiento de datos. Los portátiles se implementaron en Google Colab para permitir la colaboración y la coedición en tiempo real y luego se transfirieron como un repositorio abierto en GitHub para el control de versiones, facilitando la transparencia y la trazabilidad de la optimización del código colaborativo. Cubren todo el proceso de datos del piloto en etapas secuenciales, que incluyen:
Etapa 1: Generación automatizada de anotaciones a partir de metadatos textuales (basados en PNL)
1i. Recupere los identificadores de los artículos en la Galería de arte popular ucraniano publicada utilizando el conjunto de usuarios de Europeana ΑPI y obtenga metadatos textuales (por ejemplo, títulos, temas) de los artefactos utilizando la API de búsqueda de Europeana.
1ii. Genere anotaciones automatizadas (etiquetas de descripción) a partir de los metadatos utilizando técnicas de procesamiento de lenguaje natural (NLP), particularmente heurística basada en reglas y reconocimiento de entidades nombradas (NER) utilizando la biblioteca de Python de código abierto spaCy.
Etapa 2: Generación automatizada de anotaciones a partir de imágenes (basadas en la visión por ordenador)
2i. Descargue artefactos de galería como imágenes utilizando la API de Europeana User Set.
2ii. Generar subtítulos de imágenes descriptivas utilizando técnicas de visión por ordenador con modelos de IA preentrenados, en particular variantes de los modelos Qwen de código abierto: modelo de lenguaje visual multimodal (VLM) Qwen3-VL-2B-Instruct y modelo de lenguaje grande (LLM) Qwen3.5-4B.
2iii. Genere anotaciones automatizadas a partir de los subtítulos de las imágenes.
Etapa 3: Preparación de anotaciones automatizadas para validación crowdsourced (formato JSON-LD)
3i. Formatee todas las anotaciones generadas basadas en el modelo de anotación W3C para la ingestión directa en la plataforma de crowdsourcing CrowdHeritage.
3ii. Convierta las anotaciones finales con formato JSON en un CSV legible por máquina y combine todas las anotaciones de los cinco talleres de crowdsourcing.
Etapa 4: Garantía de calidad de los datos y cribado consciente de los sesgos de las anotaciones validadas por el ser humano
4i. Verifique las anotaciones finales contra términos dañinos, sesgados o polémicos en el Vocabulario DE-BIAS a través de la consulta de tesauros basada en RDF.
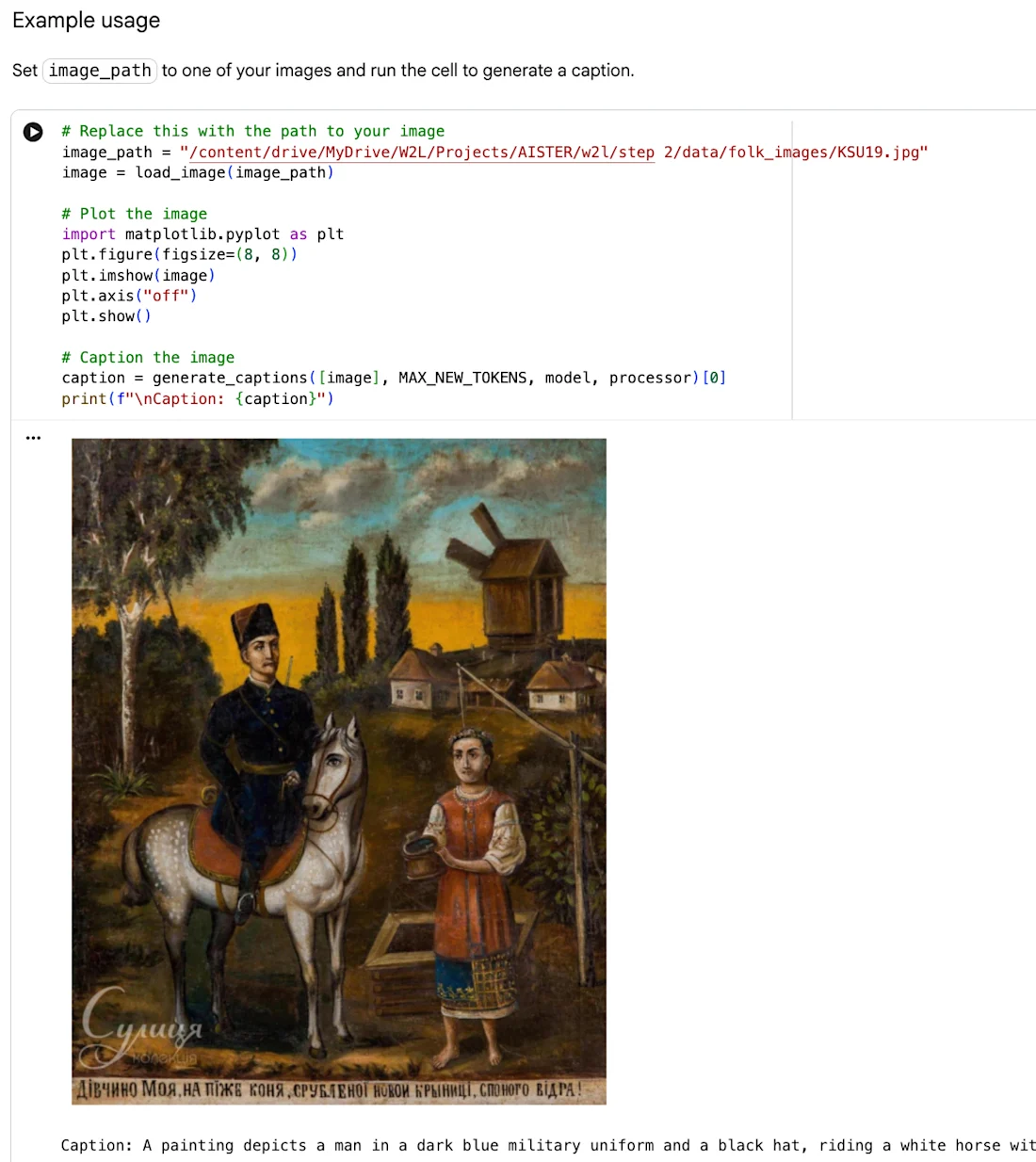
En el transcurso de cinco talleres de crowdsourcing celebrados in situ y en línea, 70 participantes, incluidos investigadores, estudiantes universitarios y expertos en arte popular, revisaron las anotaciones generadas por IA, confirmando etiquetas precisas, rechazando las engañosas a través de votos positivos y negativos y contribuyendo con anotaciones adicionales propias.
Perspectivas de datos y evaluación ética
La mayoría de las imágenes se enriquecieron con 15 a 20 nuevas etiquetas descriptivas cada una. En general, se registraron casi 55,000 acciones de anotación, incluida la generación de etiquetas, votos positivos y votos negativos. El resultado es la apertura de vías más ricas para descubrir y relacionarse con el arte popular ucraniano. Las métricas posteriores a la campaña revelan que la mayoría de las anotaciones generadas por IA se aceptaron como precisas, y solo unas pocas fueron rechazadas.
Estas cinco etiquetas generadas por IA recibieron las tasas de aceptación más altas:
- icono
- pintura
- hombre
- árboles
- mujer.
Estas cinco etiquetas generadas por IA recibieron las tasas de rechazo más altas:
- grietas
- desgaste
- daños
- objeto pequeño
- personal.
La aplicación de una evaluación de impacto ética a las anotaciones finales se consideró un paso importante en el proyecto piloto. Se llevó a cabo una segunda etapa de examen para identificar el lenguaje potencialmente problemático y fortalecer la rendición de cuentas. La selección de las etiquetas aprobadas por humanos contra el Vocabulario DE-BIAS identificó un término, esclavo, que posteriormente se revisó a persona esclavizada según la recomendación. El vocabulario se aplicó como medida de evaluación de impacto ético antes de la publicación definitiva del conjunto de datos abiertos, teniendo en cuenta la Recomendación de la UNESCO sobre la ética de la inteligencia artificial (2022) y la herramienta de evaluación de impacto ético (2023).
El desarrollo del proyecto piloto y la comprensión de sus dimensiones éticas relacionadas con la IA también se basaron en el estudio de análisis de datos de AISTER, que cartografió veintidós proyectos de investigación internacionales que utilizan la inteligencia artificial y la participación ciudadana para la preservación del patrimonio cultural en contextos de emergencia. El estudio clasificó los proyectos seleccionados utilizando el marco de clasificación AISTER, que ofrece una categorización sistemática en veinticuatro dimensiones analíticas diseñadas para analizar iniciativas de patrimonio participativo impulsadas por la IA. Las dimensiones del marco incluyen los ámbitos del patrimonio cultural, el modelo de participación ciudadana (Shirk et al., 2012) y el modelo de cooperación (Carayannis & Campbell, 2009), junto con las dimensiones específicas de la IA, incluidos los tipos de tecnología de IA, el modelo de agente racional (Russell & Norvig, 2020, 4a ed.), la tipología ética aplicada de la IA (Morley et al., 2019), los tipos de licencia y más. Los datos del estudio se publican como visualizaciones web interactivas de acceso abierto que ofrecen una exploración comparativa del campo. El flujo de trabajo piloto y los hallazgos se publican en un próximo documento de conferencia (Ziku, Zourou, & Kouzelis, 2026).
Conclusiones
El piloto se propuso crear una vía abierta y reproducible para el uso de herramientas de IA para procesar datos a escala, combinada con la participación humana, la evaluación ética y la comprensión de los datos, para apoyar formas más precisas, responsables, basadas en métricas y enriquecidas de descubrir el arte popular ucraniano. A veces, el viaje fortuito hacia el patrimonio comienza con la palabra escrita en un cuadro de búsqueda. Y a veces, las palabras correctas pueden sacar a la luz una nueva colección.
Los tres contribuyentes más activos a la campaña de crowdsourcing recibieron un honorario, así como insignias de oro, plata y bronce, respectivamente: Inna Kaika, estudiante de Lengua Inglesa y Literatura Extranjera, Universidad Estatal Mykola Gogol; Daria Markova, estudiante de Traducción de la Universidad Técnica Estatal de Pryazovskyi; Marko Lakhmatov, estudiante de Ciberseguridad, Universidad Técnica Estatal de Pryazovskyi.
Reflexionando sobre su participación, Inna compartió: «El arte ucraniano refleja la resiliencia y la creatividad de nuestro pueblo, y compartirlo es más importante que nunca. Impulsado por esta pasión, me uní a la campaña para hacer el patrimonio cultural más accesible. Me gustó especialmente el proceso de anotación y la exploración de la colección etnográfica. Fue un honor contribuir a un proyecto que aúna arte y tecnología».
Explorar y reutilizar los recursos piloto
¿Interesado en aplicar métodos similares a sus propias colecciones?
- Vea la campaña de crowdsourcing para el arte popular ucraniano en CrowdHeritage.
- Explore el piloto de crowdsourcing humano en el bucle.
- Reutilizar los Cuadernos Jupyter de código abierto, que documentan todo el flujo de trabajo desde la recuperación de datos hasta las anotaciones generadas por IA y las exportaciones listas para plataformas.
- Acceder a los conjuntos de datos abiertos del repositorio abierto de Zenodo, que incluyen los datos y resultados del piloto para su conservación, citación y reutilización.
- Explore las visualizaciones interactivas de datos y descubra las ideas de 22 iniciativas de investigación internacionales que utilizan la IA y la participación ciudadana para la preservación del patrimonio cultural en entornos de emergencia y más allá.
Agradecimientos
Nos gustaría agradecer a todos los socios y colaboradores del proyecto AISTER, y en particular a Yevgen Dmytruk en el Museo Krovets, Eirini Kaldeli en CrowdHeritage y Datoptron, Hugo Manguinhas en la Fundación Europeana, y Uldis Zariņš y Sanita Reinsone en la Universidad de Letonia.
Referencias seleccionadas
- La documentación de los Cuadernos Jupyter sigue los criterios de evaluación de la calidad de los proyectos Jupyter por parte de las instituciones GLAM, publicados en Candela, G., Chambers, S., & Sherratt, T. (2023). Un enfoque para evaluar la calidad de los proyectos Jupyter publicado por las instituciones GLAM. Revista de la Asociación para la Ciencia y la Tecnología de la Información, 74(13), 1550-1564.
- La documentación README del piloto sobre GitHub adopta la estructura de la documentación del conjunto de datos de KU Leuven Libraries Git. Véase: KU Leuven Libraries, Departamento de Digitalización. (2019). The Portraits Collection Dataset of KU Leuven Libraries, Special Collections (Versión 01-beta2) [Conjunto de datos]. Zenodo (en inglés).
- M. Ziku, K. Zourou, y A. Kouzelis, 'AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow», 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Venecia (Italia), 7-9 de septiembre de 2026, en prensa.