
Prečítajte si o reprodukovateľnom pilotnom projekte, v ktorom sa kombinovalo používanie platformy Europeana.eu a rozhraní API, vopred vyškolených modelov umelej inteligencie, modelovania živých kódov a sémantických údajov, ľudských prispievateľov na platforme crowdsourcingu, nástroja tezauru so zaujatosťou a metriky údajov, čo viedlo k obohateniu ukrajinskej etnografickej zbierky na platforme Europeana.eu prostredníctvom 55 000 anotačných akcií a takmer 6 000 nových značiek metaúdajov.
Ochrana ukrajinského dedičstva pod vedením občanov
Web2Learn spolu s Luxemburskými univerzitami, Lotyšskom, Kyjevom Tarasom Ševčenkom a nadáciou Europeana od roku 2025 spolupracuje na projekte programu Erasmus+ AISTER, ktorý sa zaoberá účasťou občanov využívajúcich umelú inteligenciu na ochrane ukrajinského kultúrneho dedičstva. Web2Learn prispieva svojimi odbornými znalosťami v inováciách orientovaných na občanov k projektu s využitím technológií s otvoreným zdrojovým kódom, ktoré podporujú vzdelávanie, odbornú prípravu a aktívne občianstvo.

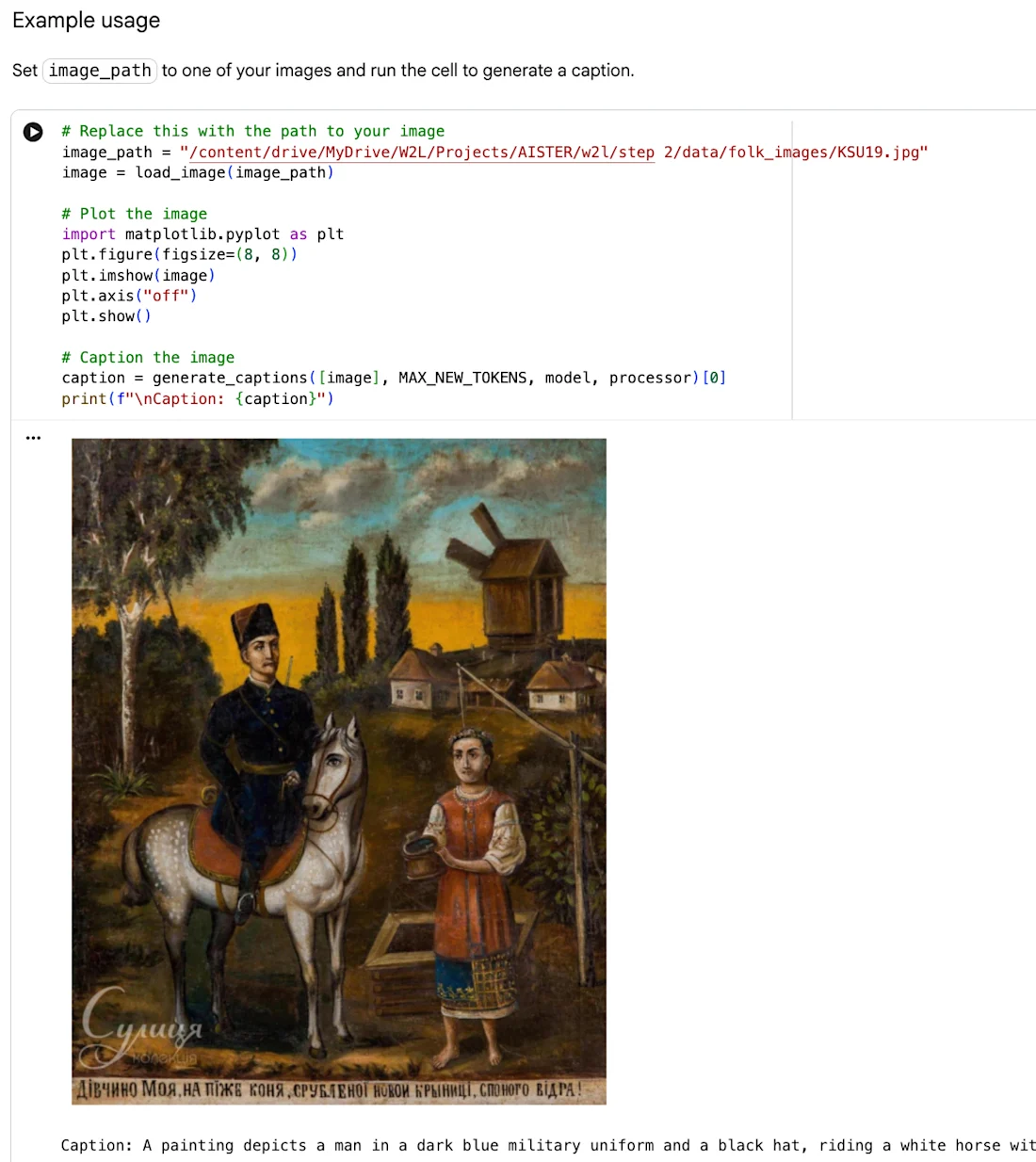
Pilotný plagát HITL Crowdsourcing od Web2Learn obsahuje ľudovú maľbu "Portrét dievčaťa", ako sa pripisuje vyššie, začlenenú do súčasnej kompozície s dodatočným povolením od držiteľa práv.
Konzorcium AISTER naplánovalo sériu seminárov so zapojením výskumných pracovníkov, študentov a mladých odborníkov počas trvania projektu. Päť seminárov pod vedením Web2Learn online a na mieste v knižnici Lotyšskej univerzity poskytlo príležitosť na spustenie pilotného projektu: otestovať pracovný postup človeka v slučke s cieľom obohatiť digitálne zbierky obrázkov prostredníctvom crowdsourcingu a nástrojov umelej inteligencie a vyzvať účastníkov seminára, aby sa zapojili do ukrajinského etnografického dedičstva a stali sa aktívnymi prispievateľmi obohatením a validáciou popisných značiek vytvorených umelou inteligenciou.
Pilotný projekt bol navrhnutý ako otvorený a reprodukovateľný zdroj s podrobnou dokumentáciou na uľahčenie výskumu a odbornej prípravy v oblasti digitálnych humanitných vied a je voľne dostupný na opätovné použitie akademickými pracovníkmi, študentmi a učiteľmi, ako aj na kreatívne opätovné použitie.
Ukrajinské ľudové umenie na Europeana.eu
V roku 2025 Krovetsovo online múzeum tradičného umenia Ukrajiny, ktoré funguje od roku 2014 vďaka dobrovoľnému úsiliu zakladateľov múzea, uverejnilo prostredníctvom agregátora MUSEU súbor údajov na Europeana.eu, ktorý obsahuje 3 840 artefaktov etnografického dedičstva vrátane tradičných krojov, textilných remesiel, ľudového umenia, materiálnej kultúry a fotografií.
Obrázky použité pre pilota pochádzajú z tejto etnografickej zbierky. V rámci pilotného projektu bola na Europeana.eu uverejnená Galéria ukrajinského ľudového umenia, ktorá poskytuje prístup k podzbierke ľudového umenia múzea, ktorá obsahuje 312 artefaktov klasifikovaných ako ľudové maľby alebo ľudové ikony. Väčšina obrazov, ktoré zobrazujú každodenný vidiecky život, folklór a náboženské témy, pochádzajú z centrálnych etnografických oblastí Ukrajiny, Strednej Podniprovie a Poltavščyny a datujú sa predovšetkým do začiatku a polovice dvadsiateho storočia.
Kolekcia sa skladá predovšetkým zo žánrových scén, krajiniek a jednotlivých portrétov. Ľudové maľby tvoria vizuálne naratívy, ktoré ponúkajú snímky vidieckej krajiny, náboženských tradícií, ľudových umeleckých motívov a každodennej materiálnej kultúry. Mnohé z detailov je ľahké si všimnúť pri pohľade na obrázky, ale nie vždy je ľahké ich nájsť prostredníctvom vyhľadávania.
Pilot crowdsourcingu človeka v slučke
Cieľom pilotného projektu bolo vytvoriť novú vrstvu viditeľnosti ukrajinského ľudového umenia. Vyvinul pracovný postup, v ktorom sa kombinuje používanie rozhraní API Europeany, metód založených na umelej inteligencii na spracovanie prirodzeného jazyka a počítačového videnia, poznámkového bloku Jupyter ako interaktívneho pracovného priestoru na reprodukovateľné kódovanie a spracovanie údajov na základe etiky spolu so zapojením verejnosti prostredníctvom platformy crowdsourcingu CrowdHeritage s cieľom vytvoriť všeobecne vyhľadávateľné, človekom overené a eticky posudzované popisné značky.
Na začiatok sa na načítanie položiek galérie a metaúdajov použili dve rozhrania API Europeany, a to rozhranie API pre používateľskú sadu Europeany na prístup ku galériám vytvoreným používateľmi uverejneným na portáli Europeana a rozhranie API pre vyhľadávanie metaúdajov Europeany na načítanie obsahu sprístupneného na portáli Europeana podľa modelu údajov Europeany (EDM). Potom boli vytvorené nové popisné anotácie pomocou nástrojov umelej inteligencie, ktoré používali modely a knižnice umelej inteligencie s otvoreným zdrojovým kódom pri spracovaní prirodzeného jazyka a počítačovom videní. Automatizované anotácie boli generované v Jupyter Notebooks a serializované v JSON-LD podľa dátového modelu webových anotácií W3C (World Wide Web Consortium) na podporu ich dovozu do crowdsourcingovej platformy CrowdHeritage spravovanej spoločnosťou Datoptron.
Celkovo pilotný projekt vyvinul osem notebookov Jupyter, ktoré fungovali ako interaktívne výpočtové prostredia, ktoré umožňujú živé kódovanie a reprodukovateľnosť na podporu vykonávania krokov spracovania údajov medzi koncovými bodmi. Notebooky boli implementované v službe Google Colab s cieľom umožniť spoluprácu a spoločné úpravy v reálnom čase a potom boli prenesené ako otvorené úložisko na GitHub na kontrolu verzií, čím sa uľahčila transparentnosť a vysledovateľnosť optimalizácie kolaboratívnych kódov. Zahŕňajú celý proces spracovania údajov pilotného projektu v postupných krokoch, ktoré zahŕňajú:
Krok 1: Automatické generovanie anotácií z textových metaúdajov (založené na NLP)
1i. Vyhľadajte ID položiek v uverejnenej Galérii ukrajinského ľudového umenia pomocou používateľskej sady Europeana ΑPI a načítajte textové metaúdaje (napr. názvy, predmety) artefaktov pomocou rozhrania Europeana Search API.
1ii. Vytvárajte automatizované anotácie (description tags) z metaúdajov pomocou techník spracovania prirodzeného jazyka (NLP), najmä heuristiky založenej na pravidlách a rozpoznávania pomenovaných entít (NER) pomocou open-source knižnice Python spaCy.
Krok 2: Automatické generovanie anotácií z obrázkov (založené na počítačovom videní)
2i. Stiahnite si artefakty galérie ako obrázky pomocou rozhrania API User Set Europeana.
2ii. Vytvárať popisné obrazové titulky pomocou techník počítačového videnia s vopred vyškolenými modelmi umelej inteligencie, najmä variantmi modelov Qwen s otvoreným zdrojovým kódom – Qwen3-VL-2B-Instruct multimodálny model vizuálneho jazyka (VLM) a Qwen3.5-4B model veľkého jazyka (LLM).
2iii. Generovanie automatických poznámok z obrázkových titulkov.
Krok 3: Príprava automatizovaných poznámok pre validáciu crowdsourced (formátovanie JSON-LD)
3i. Formátovať všetky generované anotácie na základe anotačného modelu W3C pre priame požitie v crowdsourcingovej platforme CrowdHeritage.
3ii. Konvertujte záverečné poznámky vo formáte JSON do strojovo čitateľného CSV a skombinujte všetky poznámky z piatich workshopov crowdsourcingu.
Krok 4: Zabezpečenie kvality údajov a skríning anotácií overených človekom s ohľadom na zaujatosť
4i. Skontrolujte konečné poznámky proti škodlivým, neobjektívnym alebo sporným výrazom v slovníku DE-BIAS prostredníctvom dotazovania tezauru založeného na RDF.
V priebehu piatich crowdsourcingových seminárov, ktoré sa konali na mieste a online, 70 účastníkov vrátane výskumných pracovníkov, vysokoškolských študentov a odborníkov na ľudové umenie preskúmalo anotácie vytvorené umelou inteligenciou, potvrdilo presné značky, odmietlo zavádzajúce značky prostredníctvom upvotes a downvotes a prispelo vlastnými dodatočnými anotáciami.
Poznatky o údajoch a etické hodnotenie
Väčšina obrázkov bola obohatená o 15 až 20 nových popisných značiek. Celkovo bolo zaznamenaných takmer 55 000 anotačných akcií vrátane generovania značiek, upvotes a downvotes. Výsledkom je otvorenie bohatších ciest na objavovanie ukrajinského ľudového umenia a zapojenie sa doň. Metriky po kampani odhaľujú, že väčšina poznámok generovaných umelou inteligenciou bola akceptovaná ako presná, pričom len niekoľko z nich bolo odmietnutých.
Týchto päť značiek vytvorených umelou inteligenciou získalo najvyššiu mieru akceptácie:
- ikona
- maľovanie
- muž
- stromy
- žena.
Týchto päť značiek vytvorených umelou inteligenciou získalo najvyššiu mieru zamietnutia:
- praskliny
- nosenie
- poškodenie
- malý predmet
- personál.
Uplatňovanie posúdenia etického vplyvu na záverečné poznámky sa považovalo za dôležitý krok v pilotnom projekte. Druhá úroveň preskúmania bola vykonaná s cieľom identifikovať potenciálne problematický jazyk a posilniť zodpovednosť. Skríning štítkov schválených človekom proti slovníku DE-BIAS identifikoval jeden termín, otroka, ktorý bol následne revidovaný na zotročenú osobu podľa odporúčania. Slovník sa použil ako opatrenie na posúdenie etického vplyvu pred uverejnením konečného otvoreného súboru údajov, pričom sa zohľadnilo odporúčanie UNESCO o etike umelej inteligencie (2022) a nástroj na posúdenie etického vplyvu (2023).
Vývoj pilotného projektu a pochopenie jeho etických rozmerov súvisiacich s umelou inteligenciou vychádzali aj zo štúdie AISTER o analýze údajov, v ktorej sa mapovalo 22 medzinárodných výskumných projektov, ktoré využívajú umelú inteligenciu a účasť občanov na zachovanie kultúrneho dedičstva v núdzových situáciách. V štúdii sa vybrané projekty klasifikovali pomocou klasifikačného rámca AISTER, ktorý ponúka systematickú kategorizáciu do 24 analytických rozmerov určených na analýzu participatívnych iniciatív v oblasti dedičstva založených na umelej inteligencii. Rámcové rozmery zahŕňajú oblasti kultúrneho dedičstva, model účasti občanov (Shirk a kol., 2012) a model spolupráce (Carayannis aamp; Campbell, 2009) spolu s rozmermi špecifickými pre umelú inteligenciu vrátane typov technológií umelej inteligencie, modelu racionálneho agenta (Russell aamp; Norvig, 2020, 4. vyd.), aplikovanej etickej typológie umelej inteligencie (Morley a kol., 2019), typov licencií a ďalších. Prehľady údajov štúdie sa uverejňujú ako interaktívne webové vizualizácie s otvoreným prístupom, ktoré ponúkajú komparatívne preskúmanie danej oblasti. Pilotný pracovný postup a zistenia sú uverejnené v pripravovanom konferenčnom dokumente (Ziku, Zourou, & Kouzelis, 2026).
Závery
Cieľom pilotného projektu bolo vytvoriť otvorenú a reprodukovateľnú cestu na používanie nástrojov umelej inteligencie na spracovanie údajov vo veľkom rozsahu v kombinácii s účasťou ľudí, etickým hodnotením a poznatkami o údajoch s cieľom podporiť presnejšie, zodpovednejšie, metriky orientované a obohatené spôsoby objavovania ukrajinského ľudového umenia. Niekedy sa serendipitous cesta do dedičstva začína slovom zadaným do vyhľadávacieho poľa. A niekedy tie správne slová môžu priniesť novú zbierku na svetlo.
Traja najaktívnejší prispievatelia do crowdsourcingovej kampane získali čestné a zlaté, strieborné a bronzové odznaky: Inna Kaika, študentka anglického jazyka a zahraničnej literatúry, Mykola Gogol State University; Daria Markova, študentka prekladu, Štátna technická univerzita Pryazovskyi; Marko Lakhmatov, študent kybernetickej bezpečnosti, Štátna technická univerzita Pryazovskyi.
Inna sa o svojej účasti podelila: „Ukrajinské umenie odráža odolnosť a tvorivosť našich ľudí a zdieľanie je dôležitejšie ako kedykoľvek predtým. Poháňaný touto vášňou som sa pripojil ku kampani na zlepšenie dostupnosti kultúrneho dedičstva. Obzvlášť sa mi páčil anotačný proces a skúmanie etnografickej zbierky. Bolo mi cťou prispieť k projektu, ktorý spája umenie a technológie.“
Preskúmať a opätovne použiť pilotné zdroje
Máte záujem aplikovať podobné metódy na svoje vlastné zbierky?
- Pozrite si crowdsourcingovú kampaň pre ukrajinské ľudové umenie na CrowdHeritage.
- Preskúmajte pilotný projekt crowdsourcingu „human-in-the-loop“.
- Opätovne použite poznámkové bloky Jupyter s otvoreným zdrojovým kódom, ktoré dokumentujú celý pracovný postup od získavania údajov po anotácie generované umelou inteligenciou a vývozy pripravené na platformu.
- Prístup k otvoreným súborom údajov v otvorenom úložisku spoločnosti Zenodo, ktoré zahŕňajú údaje a výstupy pilotného projektu na účely uchovávania, citácie a opätovného použitia.
- Preskúmajte interaktívne vizualizácie údajov a objavte poznatky z 22 medzinárodných výskumných iniciatív, ktoré využívajú umelú inteligenciu a účasť občanov na zachovanie kultúrneho dedičstva v núdzových situáciách aj mimo nich.
Poďakovanie
Chceli by sme poďakovať všetkým partnerom a spolupracovníkom projektu AISTER, najmä Jevgenovi Dmytrukovi z Kroveckého múzea, Eirini Kaldeliovej z CrowdHeritage a Datoptronu, Hugovi Manguinhasovi z Europeany a Uldisovi Zariņšovi a Sanite Reinsoneovej z Lotyšskej univerzity.
Vybrané referencie
- Dokumentácia Jupyter Notebooks sa riadi kritériami hodnotenia kvality projektov Jupyter inštitúciami GLAM, ako boli uverejnené v Candela, G., Chambers, S., & Sherratt, T. (2023). Prístup k hodnoteniu kvality projektov Jupyter uverejnených inštitúciami GLAM. Journal of the Association for Information Science and Technology, 74(13), 1550 – 1564.
- V pilotnej dokumentácii README o GitHube sa prijíma štruktúra dokumentácie súboru údajov KU Leuven Libraries Git. Pozri: KU Leuven Knižnice, oddelenie digitalizácie. (2019). Súbor údajov o zbere portrétov KU Leuven Libraries, špeciálne zbierky (verzia 01-beta2) [súbor údajov]. Zenodo.
- M. Ziku, K. Zourou a A. Kouzelis, AI-Assisted Metadata Enrichment for Ethnographic Heritage: A Reproducible Human-in-the-Loop Crowdsourcing Workflow, 2026 IEEE International Conference on Cyber Humanities (IEEE-CH), Benátky, Taliansko, 7. – 9. septembra 2026, v tlači.